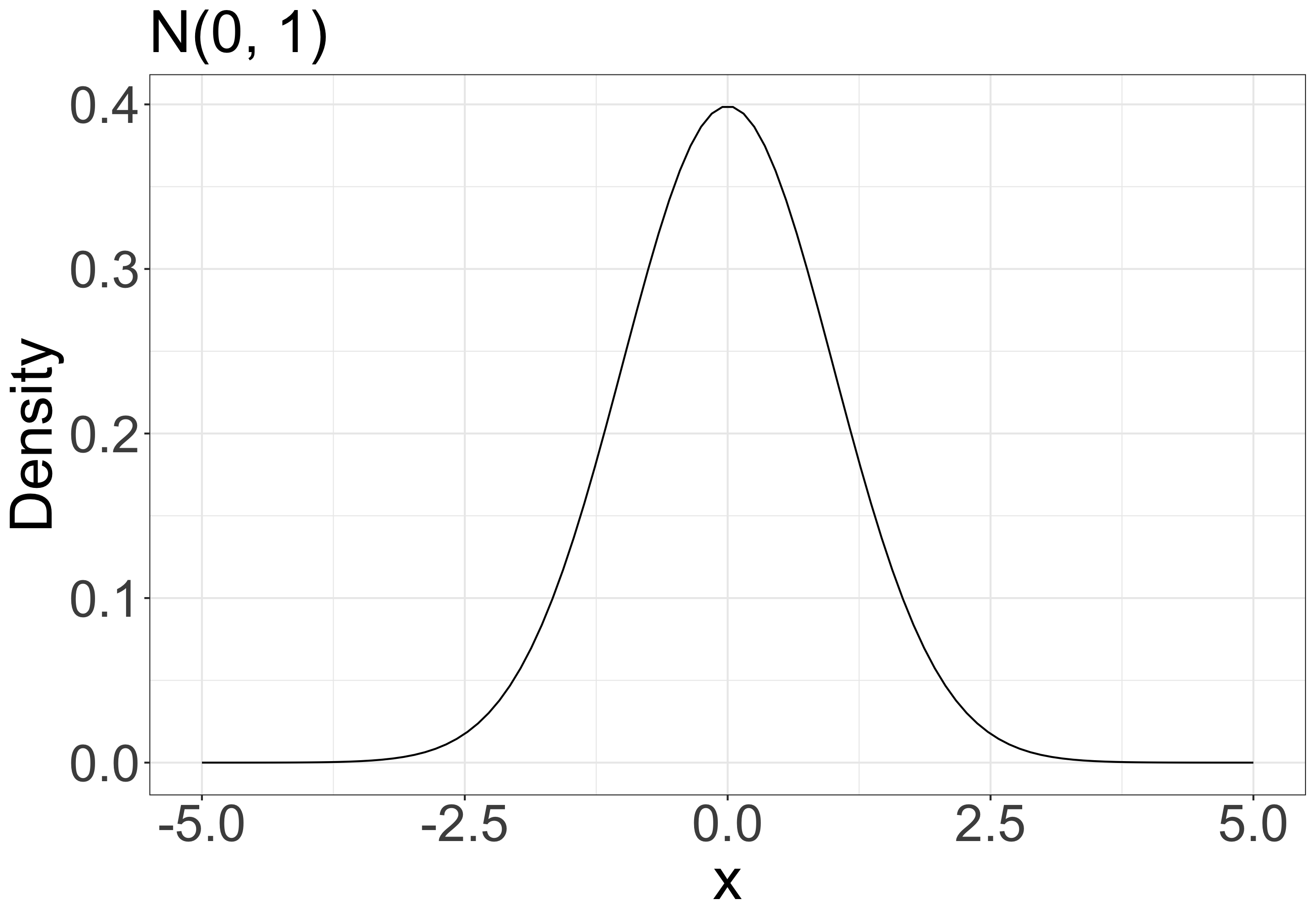
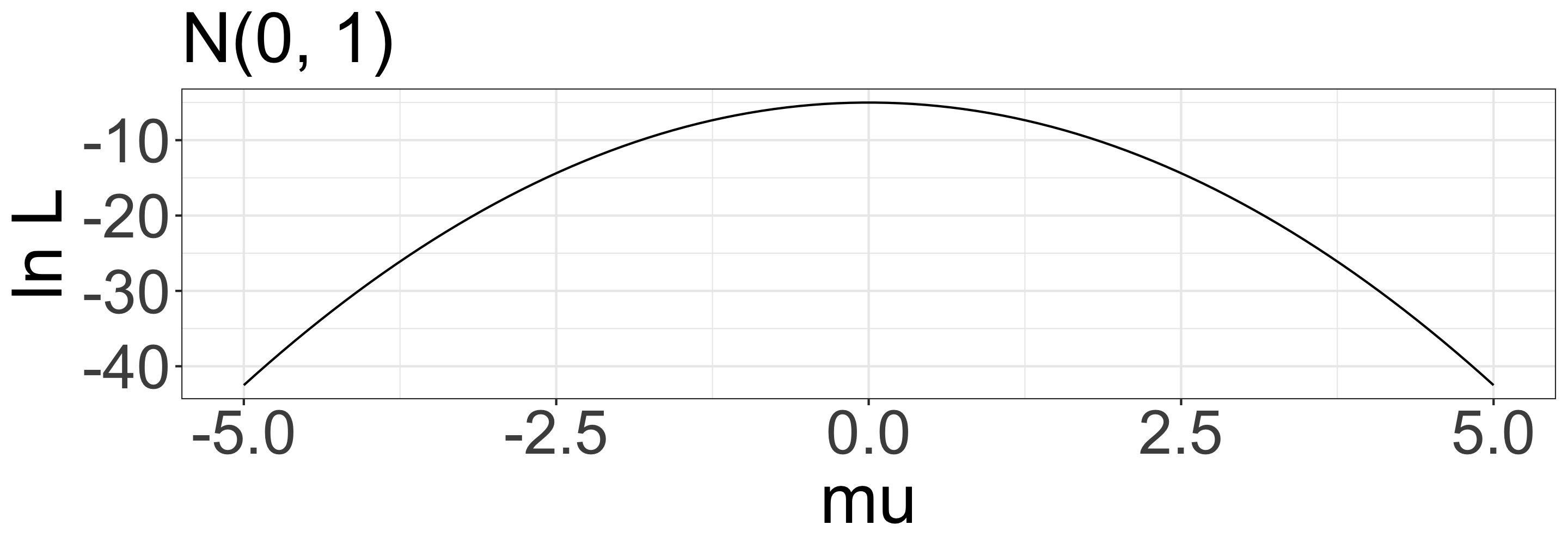
Likelihood
When your data is x = {-1.5, 0, 1.5} and your model is \(x \sim \mathcal{N}(0, 1)\), what is the probability of observing x?
- \(L = P(-1.5 \mid 0, 1) \times P(0 \mid 0, 1) \times P(1.5 \mid 0, 1)\)
- \(\mathrm{ln}\;L = \mathrm{ln}\;P(-1.5 \mid 0, 1) + \mathrm{ln}\;P(0 \mid 0, 1) + \mathrm{ln}\;P(1.5 \mid 0, 1)\)
Maximum Likelihood Estimation (MLE)
- 2 survivors out of 5 seedlings: What is the survival probability of seedlings?

\(p\): survival rates, \(1-p\): mortality rate
\(L = {}_5C_2 p^2(1-p)^3\) (Binomial distribution)
\(\mathrm{ln}\;L = \mathrm{ln}\;{}_5C_2 + 2\mathrm{ln}\;p + 3\mathrm{ln}(1-p)\)
\(\frac{d\mathrm{ln}\;L}{dt} = \frac{2}{p} - \frac{3}{1-p} = 0\)
\(p = \frac{2}{5}\)

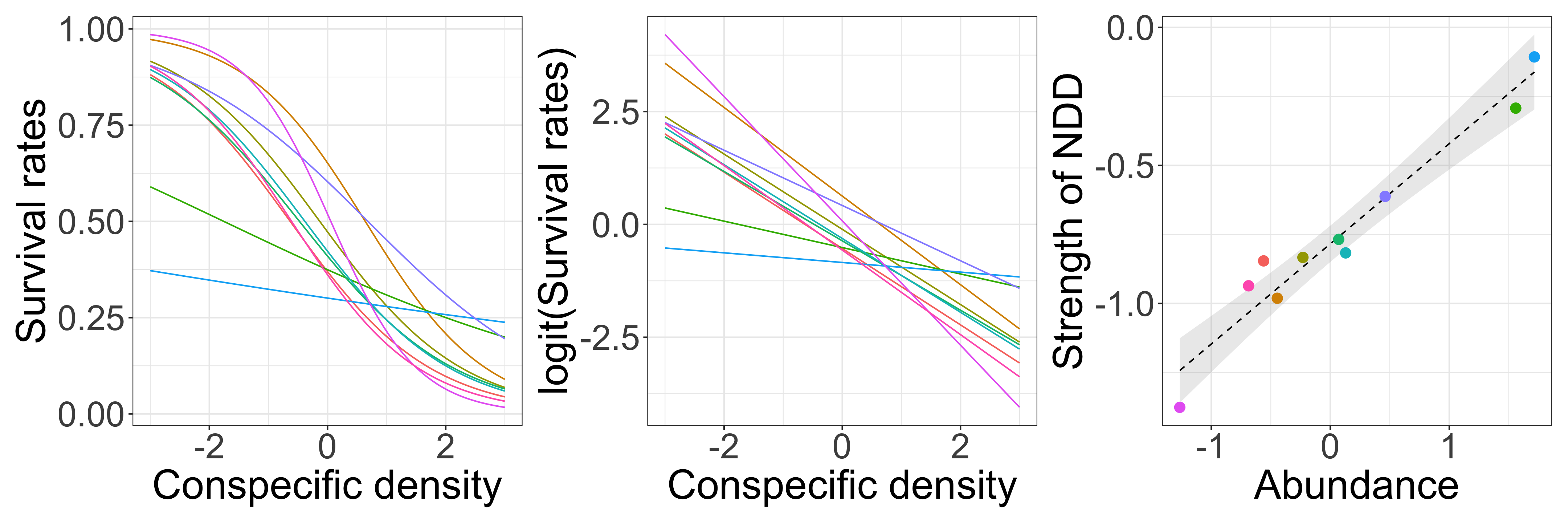
Negative density dependence (NDD)
“…rare species suffered more from the presence of conspecific neighbors than common species did, suggesting that conspecific density dependence shapes species abundances in diverse communities.”
- Comita et al. 2010 -
Multilevel model (NDD: verbal model)
There is negative density dependence (NDD) of seedling survival rate, and the strength of NDD varies among species. The strength of NDD depends on species abundance.
- Model survival rates as a function of conspecific seedling density (individual-level).
- Model the strength of NDD (i.e., slopes) as a function of species abundance (group-level).
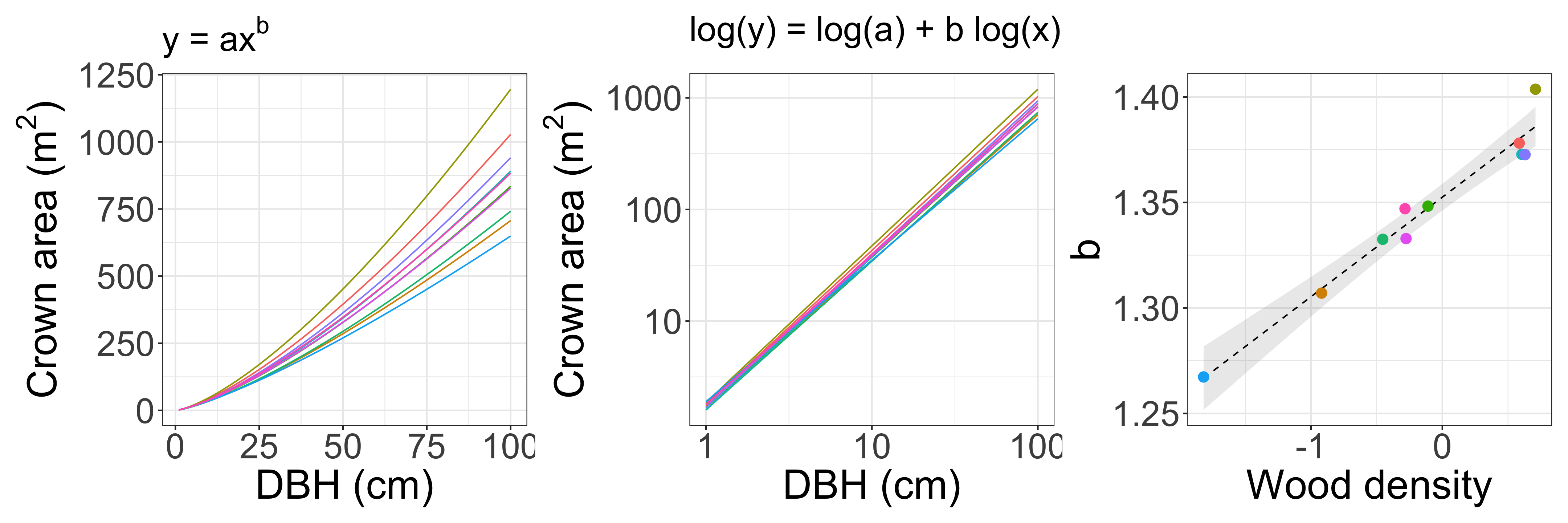
Multilevel model (tree allometry: verbal model)
There is a power-law relationship (\(y = ax^b\)) between tree diameter (DBH) and crown area, and the power-law exponent varies among species. Those relationships depend on wood density.
Model crown area as a function of DBH (individual-level).
Model the coefficient b as a function of wood density (group-level).
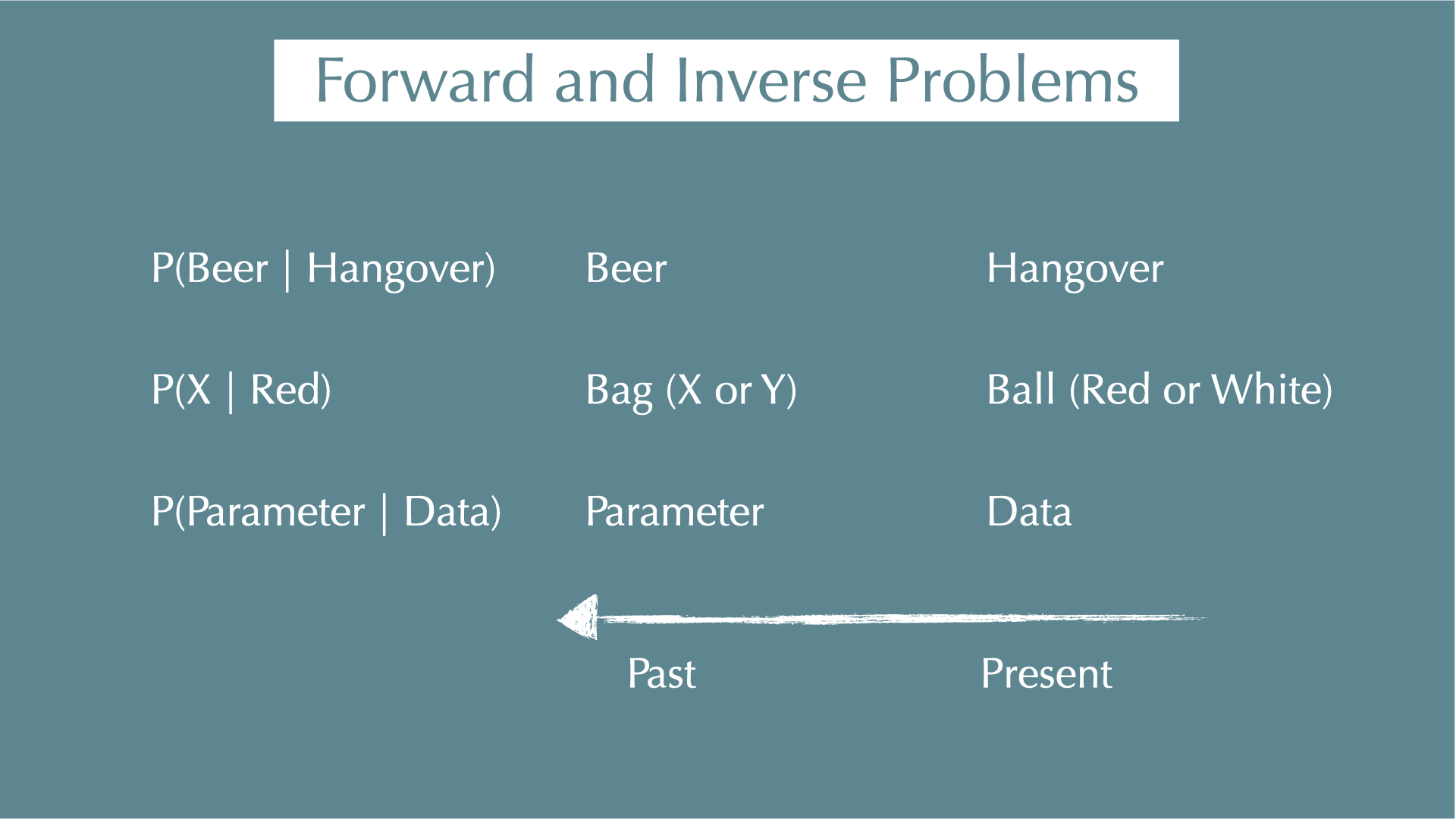
Probability
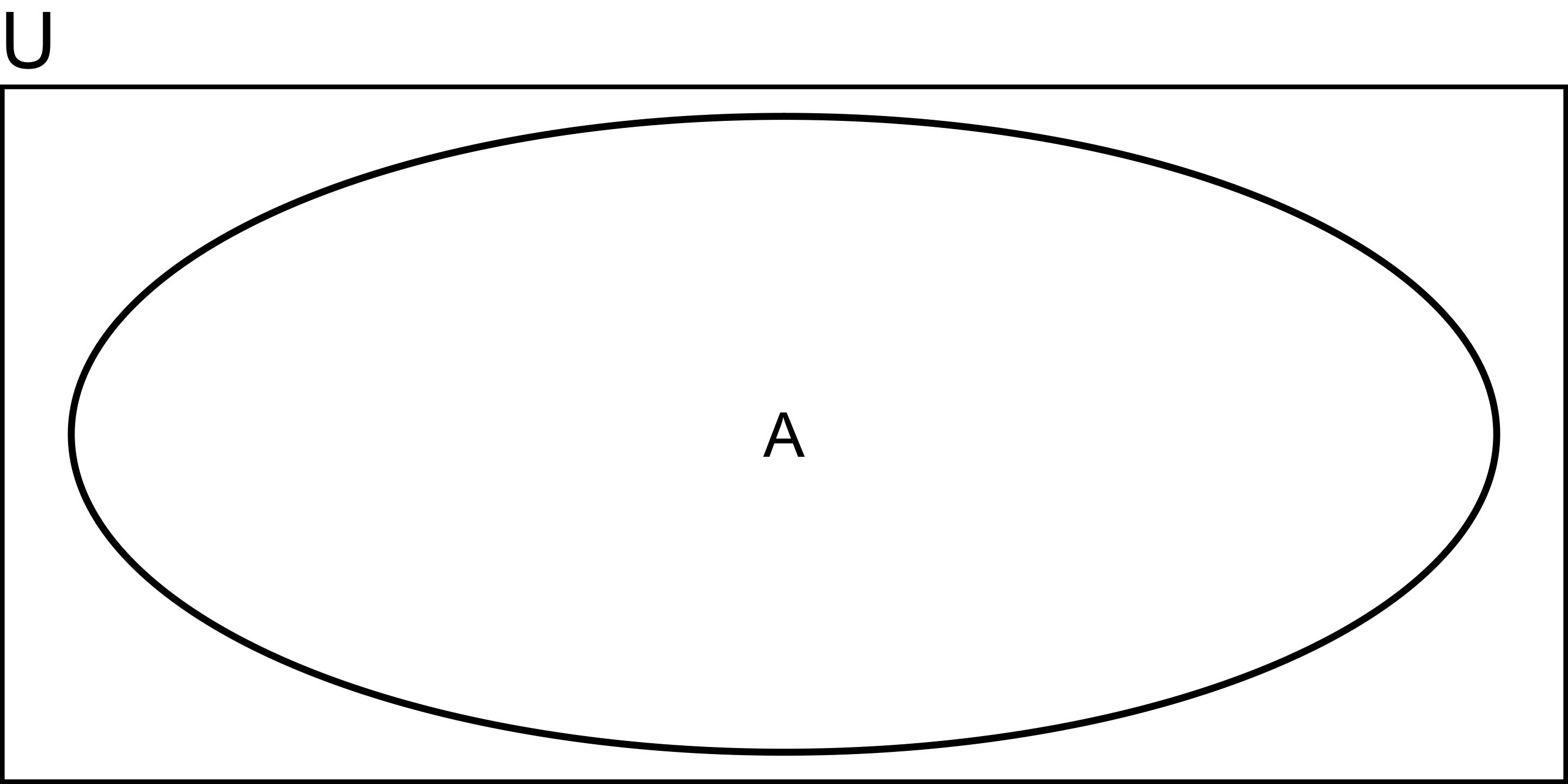
Probility of A:
\[ P(A) = \frac{A}{U} \]
e.g., probability of rolling a dice and getting an odd number is 3/6 = 1/2
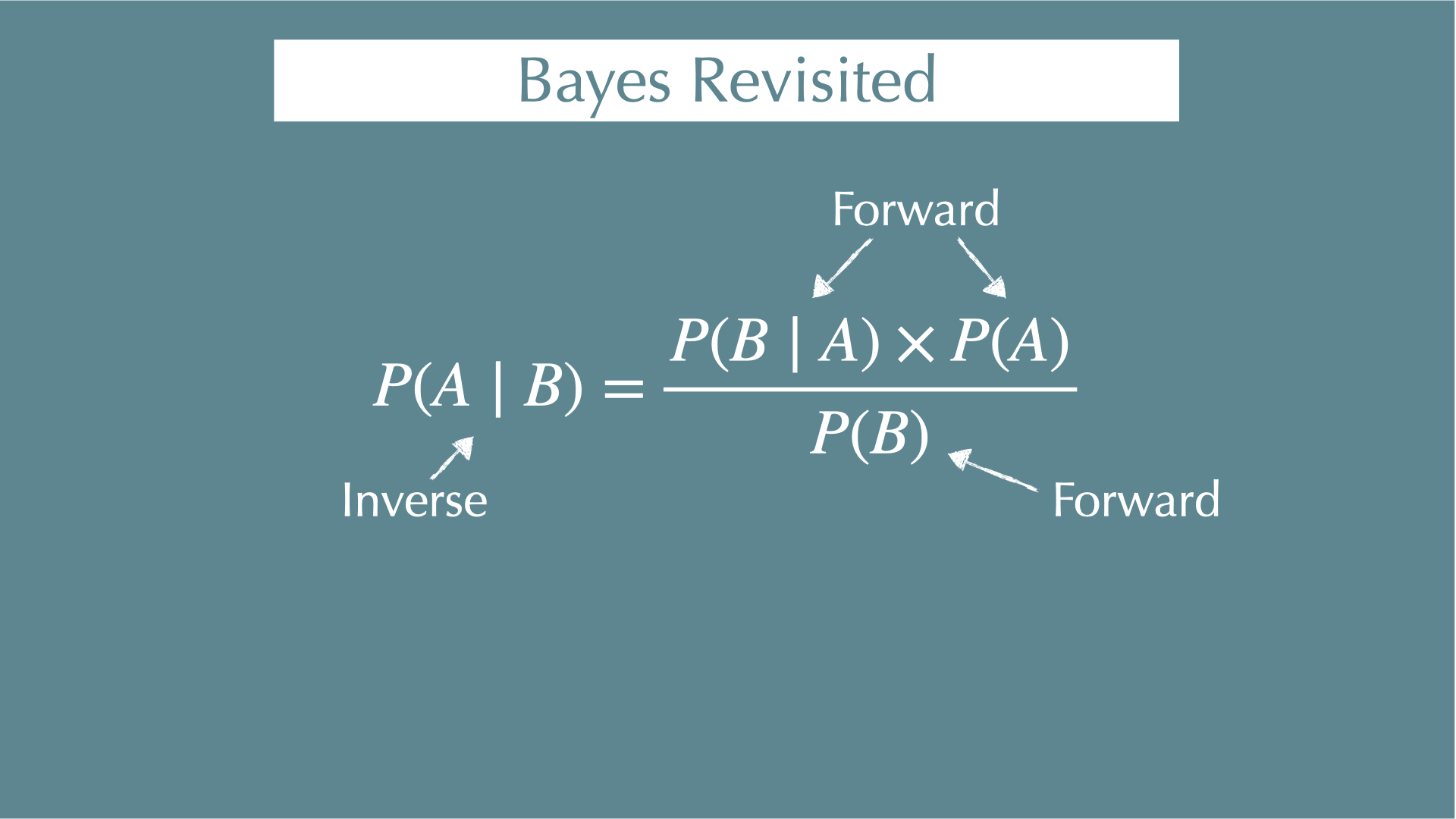
Conditional Probability
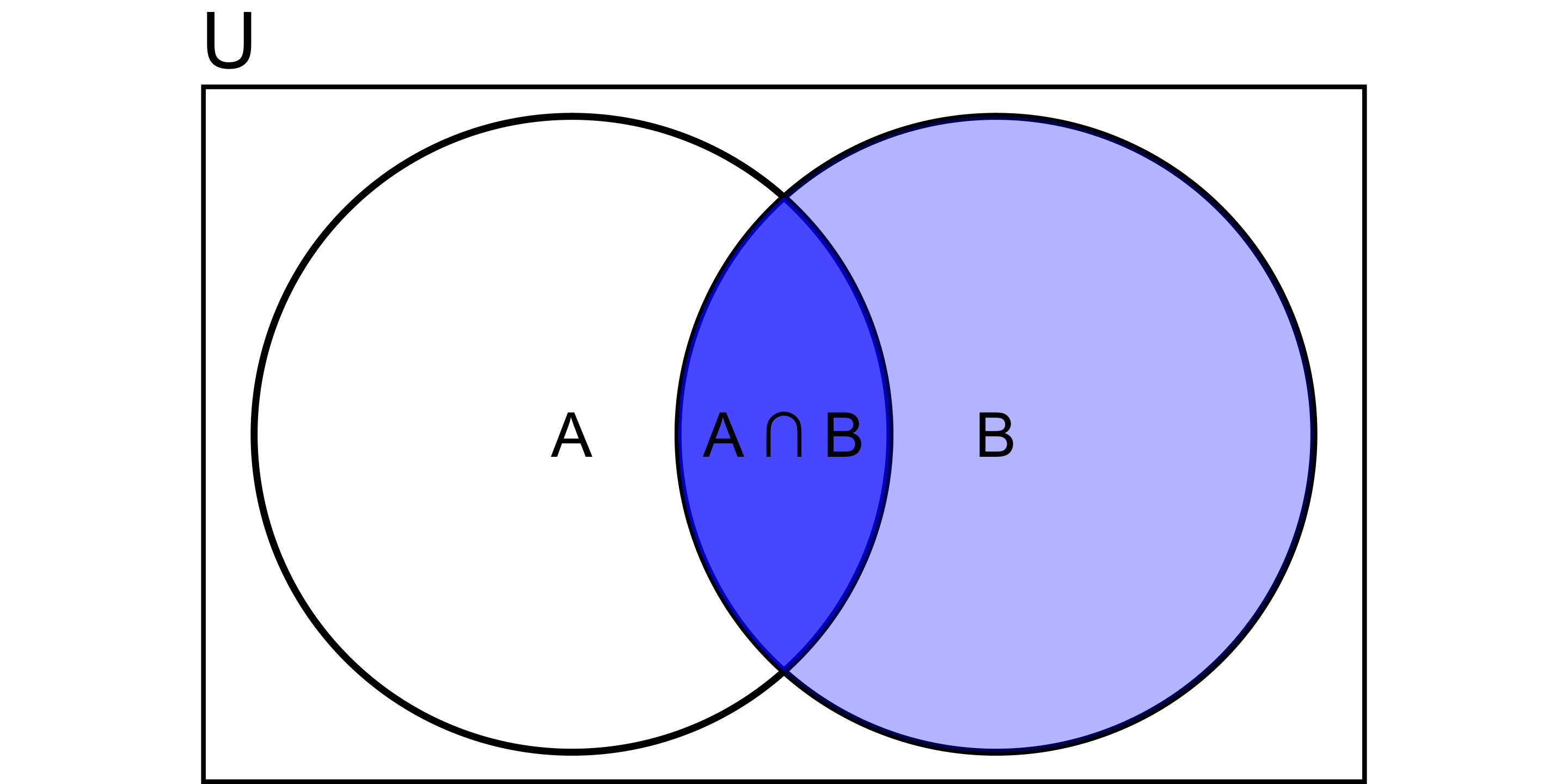
Probability of A occurring given B has already occurred:
\[ P(A \mid B) = \frac{P(A \cap B)}{P(B)} \]
e.g.,
- P(hangover) = 4%
- P(hangover | beer) = 6%.
- P(hangover | baiju) = 85%.




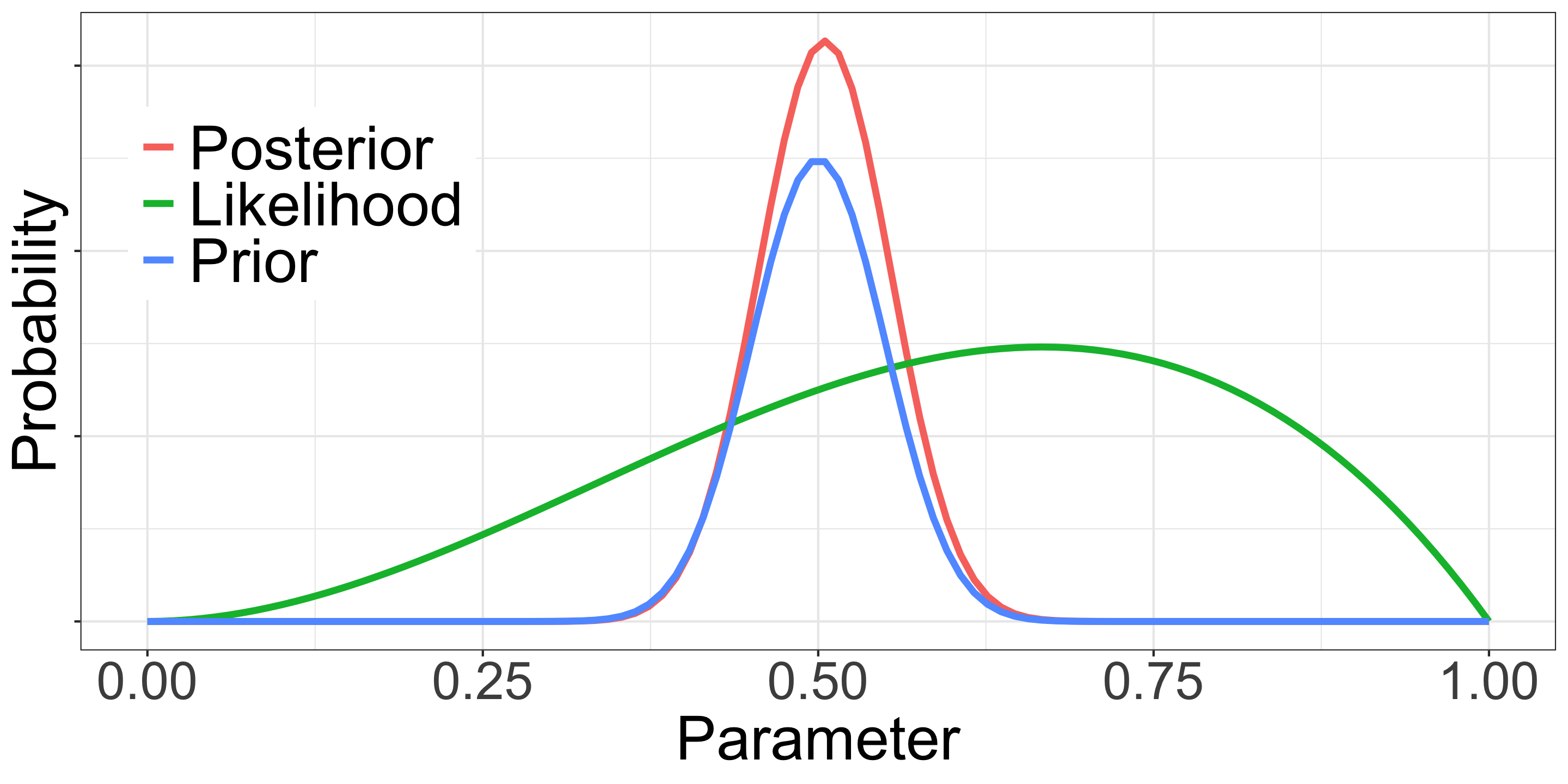
Prior
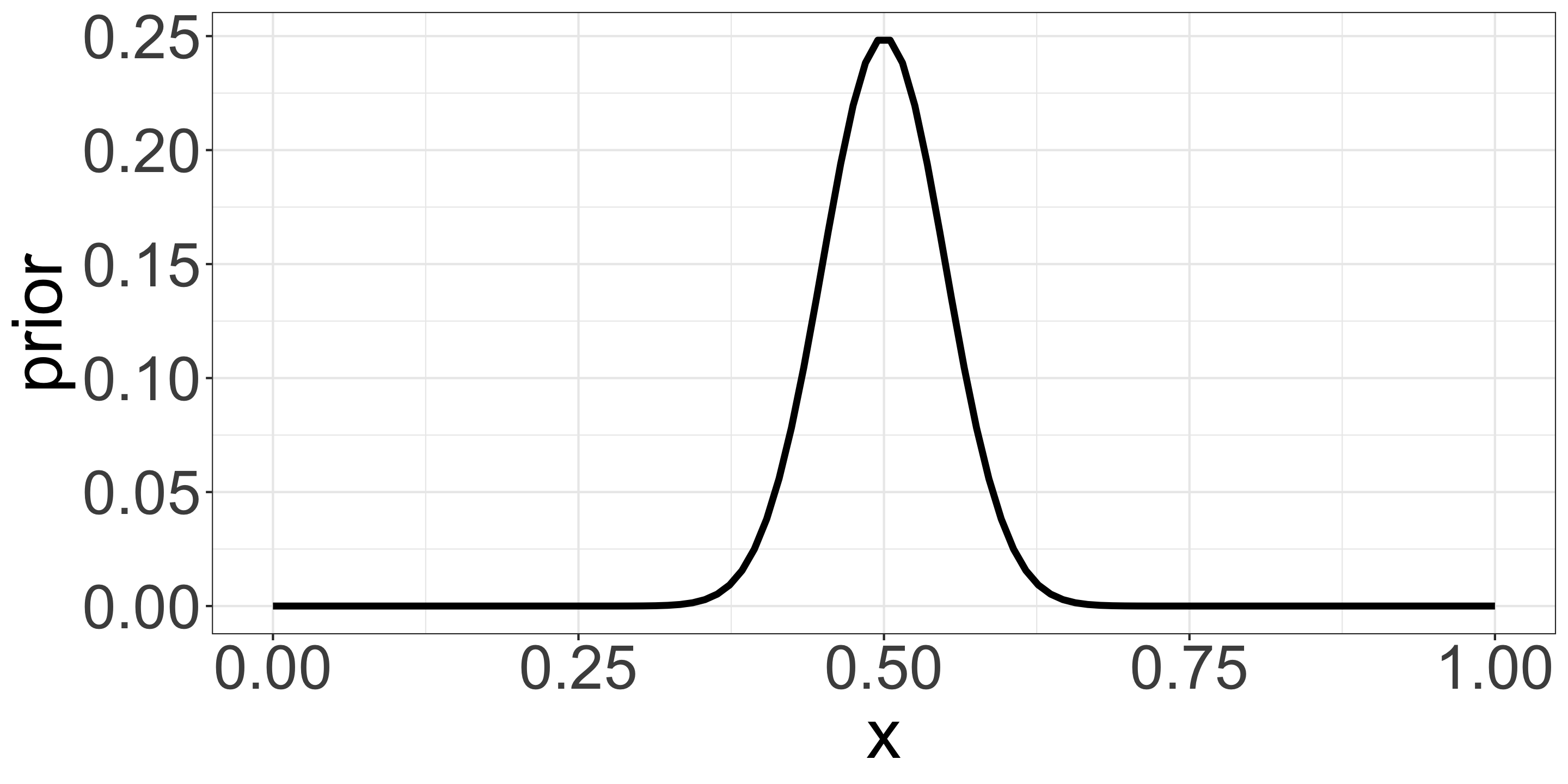
Prior (coins)
MLE
- A: 2 head out of 3 tosses -> 2/3 = 0.666
- B: 60 heads out of 100 tosses -> 60/100 = 0.6
Bayesian
\(L_A = {}_3C_2 p^2 (1-p)^1\)
\(L_B = {}_{100}C_{60} p^{60} (1-p)^{40}\)
\(\mathrm{Prior} \propto p^{50} (1-p)^{50}\)
- Beta distribution with mean 0.5 and small variance
Priors and ecology (simple linear model; y = ax + b)
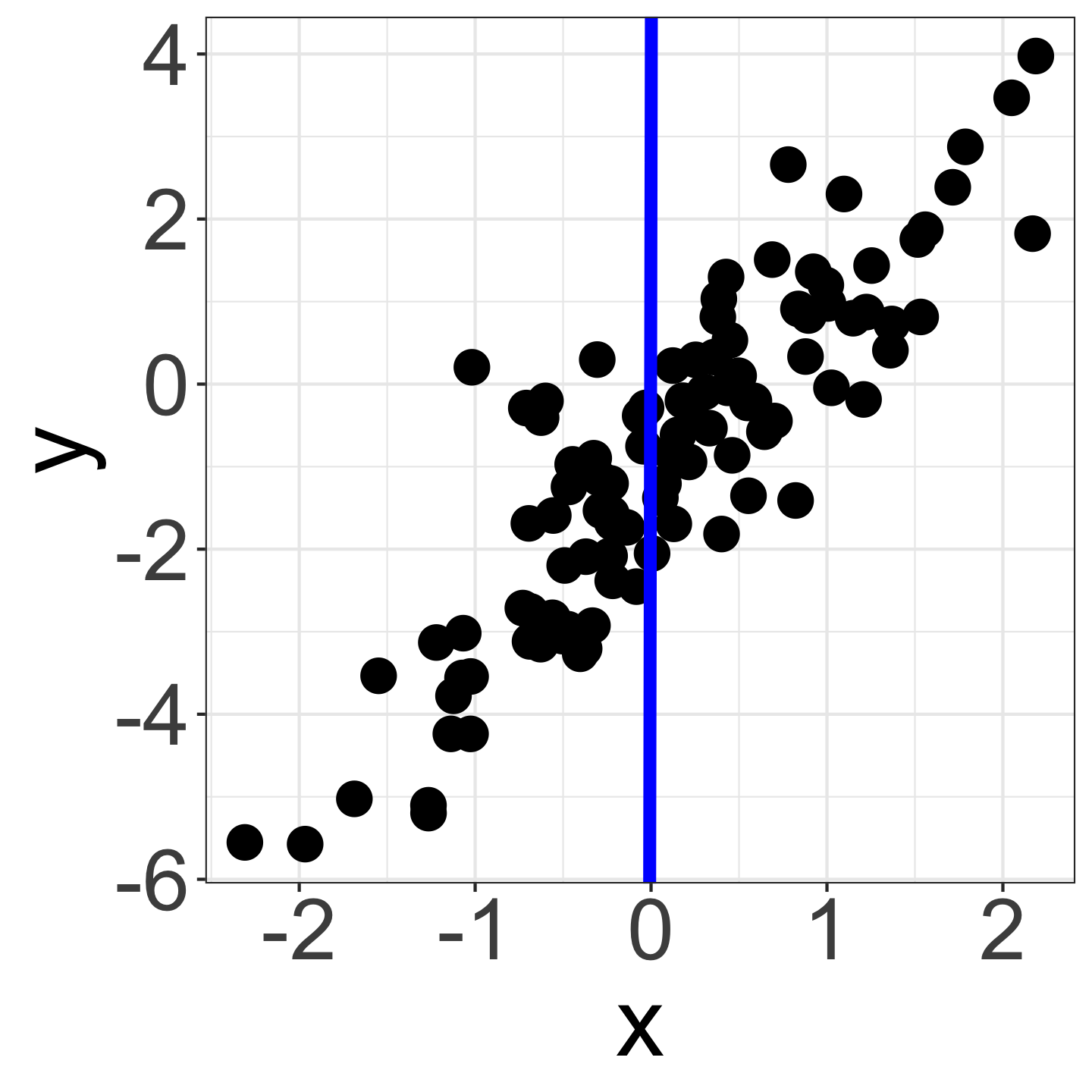
- Considering variables x = {-3, …, 3} and y = {-6, …, 4}. At this point, we don’t know if there is a correlation between x and y.
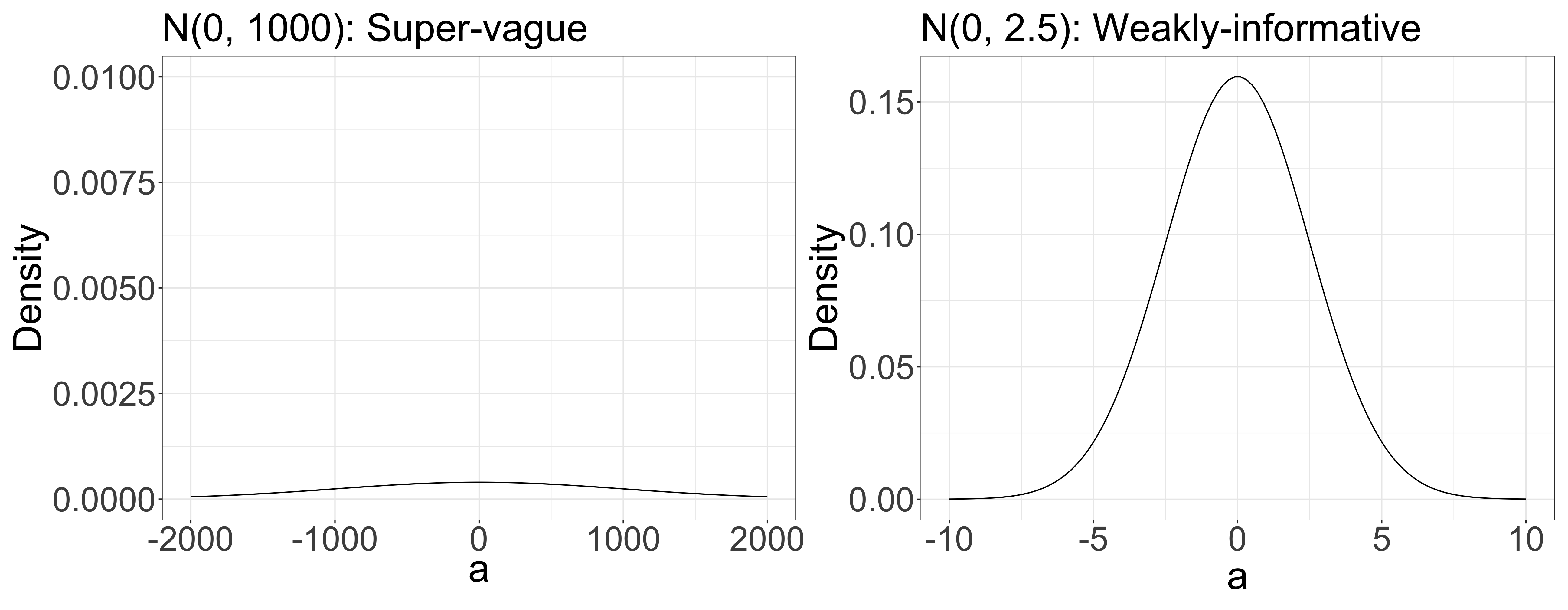
- However, given the similar scales of x and y, it’s reasonable to guess that a falls within a narrow range (-1000 < a < 1000 or -5 < a < 5 ?).
- For example, y = 100 x + 2 doesn’t work (blue line).
Priors and ecology (simple linear model; y = ax + b)
- Considering variables x = {-3, …, 3} and y = {-6, …, 4}. At this point, we don’t know if there is a correlation between x and y.
- However, given the similar scales of x and y, it’s reasonable to guess that a falls within a narrow range (-1000 < a < 1000 or -5 < a < 5 ?).
Priors and ecology (multilevel model: group-level differences)
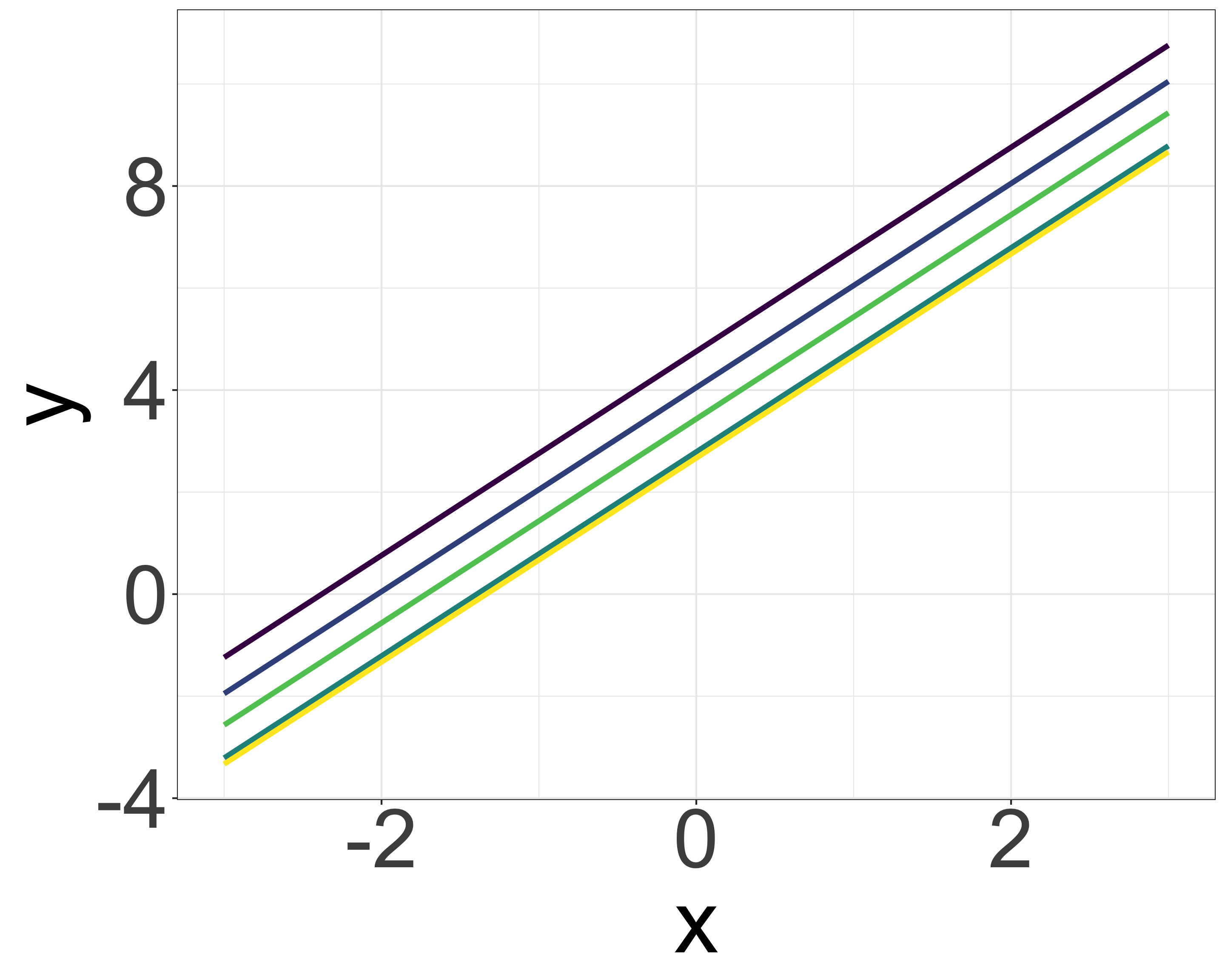
- \(y_i = ax_i + b_j\)
- If the parameter \(b_j\) is similar within each group (e.g., species differences, site differences):
- Likelihood: \(y_i \sim \mathcal{N}(ax_i + b_j, \sigma)\)
- Prior: \(b_j \sim \mathcal{N}(\mu_b, \tau)\)
Priors and ecology (multilevel model: autocorealtion)

- If the data \(y_i\) is similar to the surrounding samples (e.g., spatial autocorrelation):
- Likelihood: \(y_i \sim \mathcal{N}(\mu + \tilde{r_i}, \sigma)\)
- Prior: \(\tilde{r_i} = r_{m, n} \sim \mathcal{N}(\phi_{m,n}, \tau)\)
- \(\phi_{m,n} = (r_{m-1, n-1} + r_{m, n-1} + r_{m+1, n-1} +\) \(r_{m-1, n} + r_{m+1, n} +\) \(r_{m+1, n-1} + r_{m+1, n} + r_{m+1, n+1})/8\)
Baseball statistics
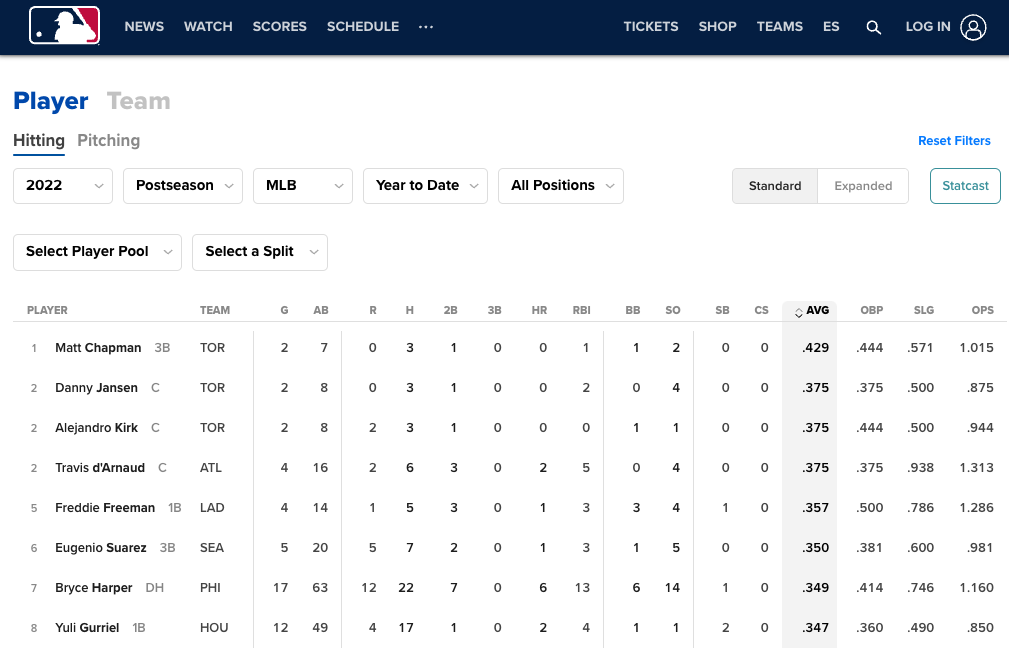
Eight school problem
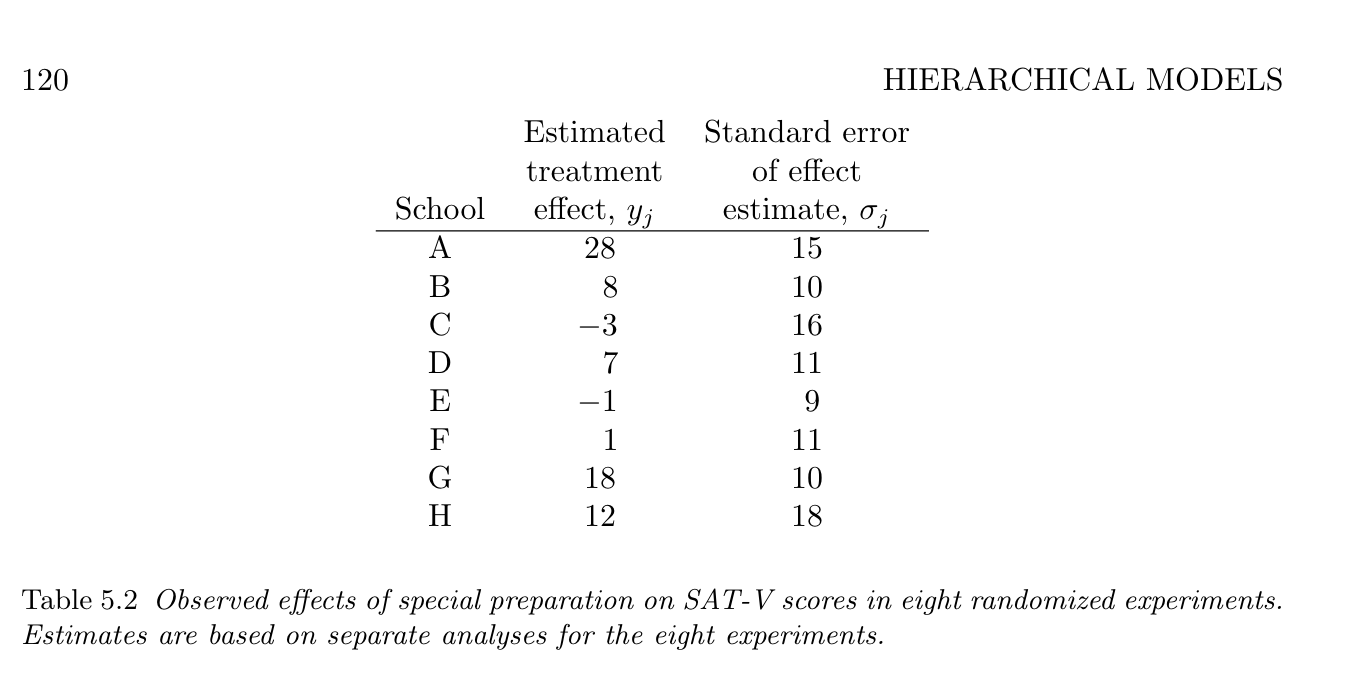
Eight species problem (separate estimates)
What is the survival rate?
| sp | n | suv | p_like | p_true |
|---|---|---|---|---|
| A | 41 | 9 | 0.22 | 0.34 |
| B | 45 | 18 | 0.40 | 0.30 |
| C | 32 | 6 | 0.19 | 0.34 |
| D | 18 | 5 | 0.28 | 0.36 |
| E | 33 | 8 | 0.24 | 0.25 |
| F | 26 | 8 | 0.31 | 0.23 |
| G | 46 | 11 | 0.24 | 0.25 |
| H | 16 | 8 | 0.50 | 0.34 |
p_trueranges [0.23, 0.36]p_likeranges [0.19, 0.5]The estimate shows the larger variation
Because of the small sample size (common in ecological studies)
Two extreme cases (pooled estimates)
- \(S_i \sim \mathcal{B}(N_i, p)\)
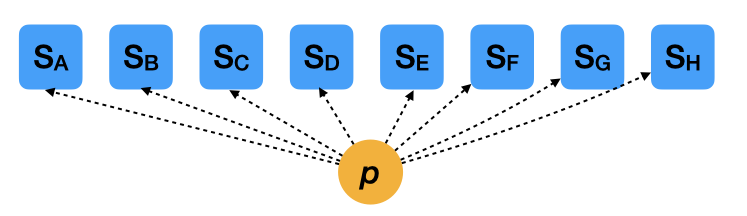
- This model doesn’t consider the variation among species
Two extreme cases (separate estimates)
- \(S_i \sim \mathcal{B}(N_i, p_i)\)
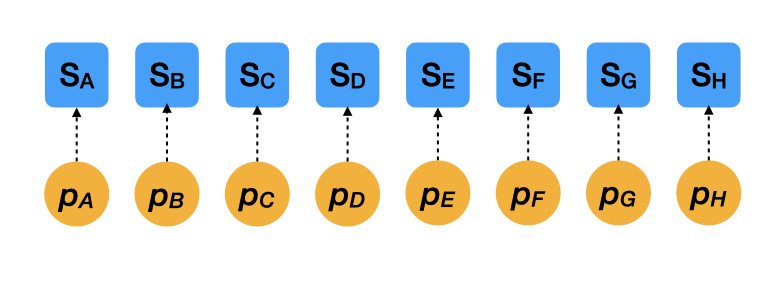
- This model assumes that survival rates are 100% independent among species
More realistic estimates (multilevel models)
\(S_i \sim \mathcal{B}(N_i, p_i)\)
\(z_i \sim \mathcal{N}(\mu, \sigma)\) where \(z_i = \mathrm{logit}(p_i) = \mathrm{log}\frac{p_i}{1 - p_i}\)
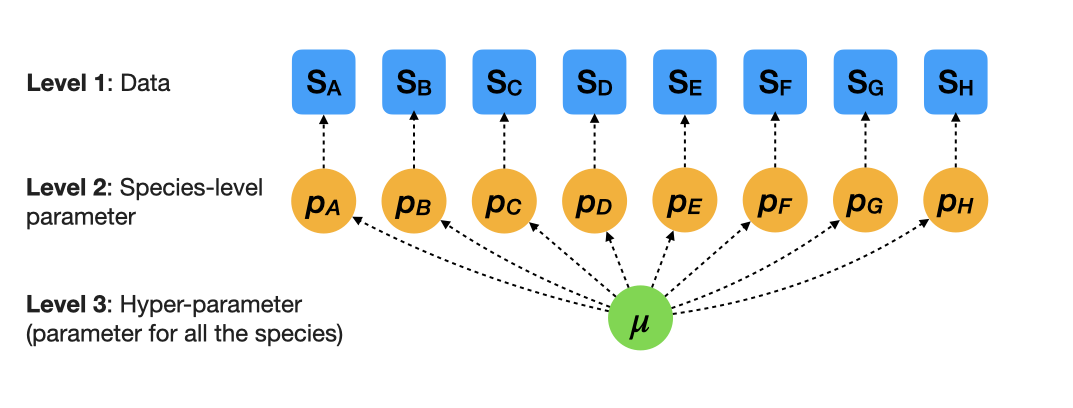
\(\sigma\) determines species variation
The overall survival rate is 0.5 in this example. We have some sense of a scale for \(\sigma\).

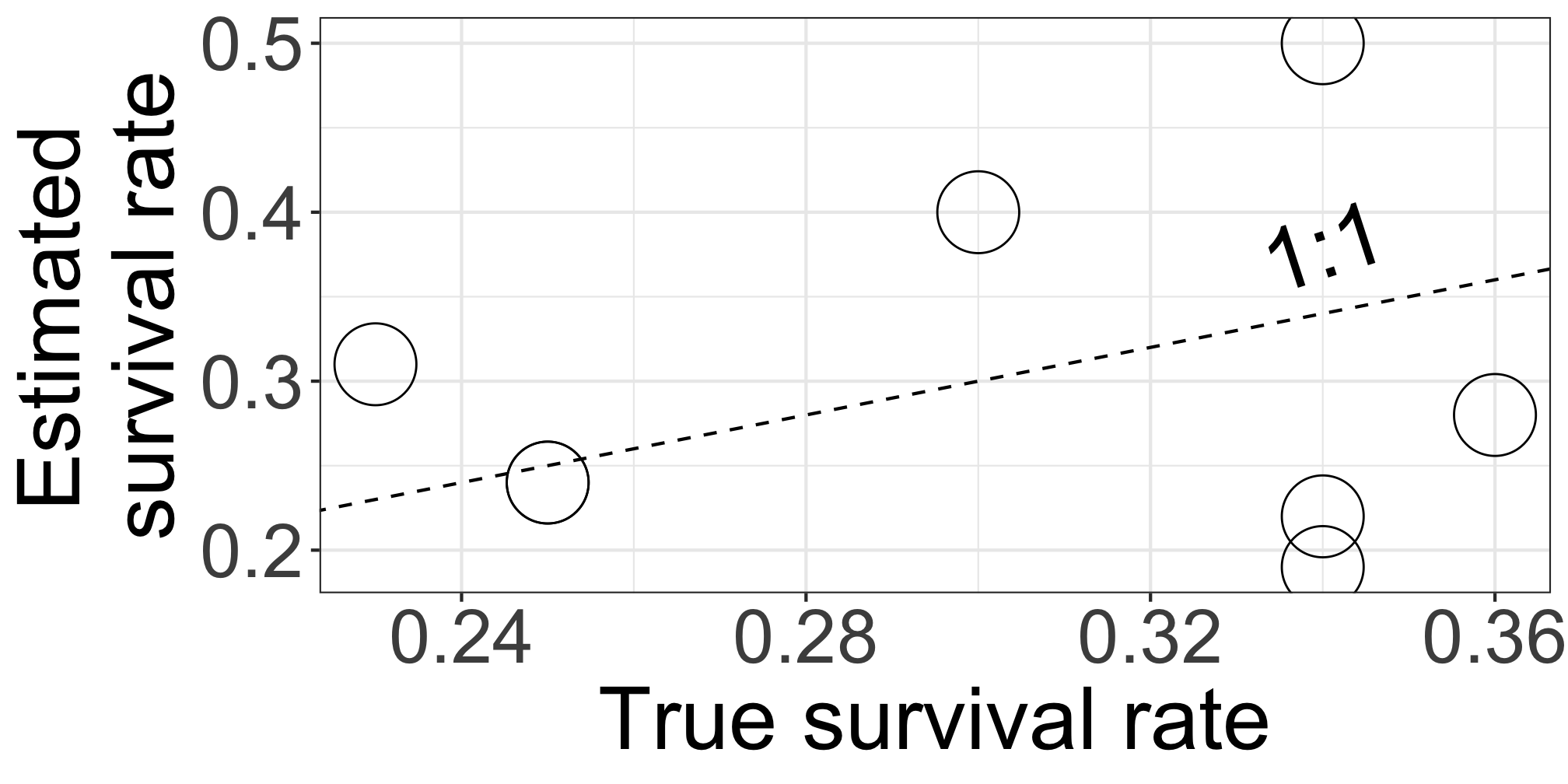
Multilevel models yield better estimates
| sp | n | suv | p_like | p_true | p_bayes |
|---|---|---|---|---|---|
| A | 41 | 9 | 0.22 | 0.34 | 0.26 |
| B | 45 | 18 | 0.40 | 0.30 | 0.33 |
| C | 32 | 6 | 0.19 | 0.34 | 0.26 |
| D | 18 | 5 | 0.28 | 0.36 | 0.28 |
| E | 33 | 8 | 0.24 | 0.25 | 0.27 |
| F | 26 | 8 | 0.31 | 0.23 | 0.29 |
| G | 46 | 11 | 0.24 | 0.25 | 0.27 |
| H | 16 | 8 | 0.50 | 0.34 | 0.32 |
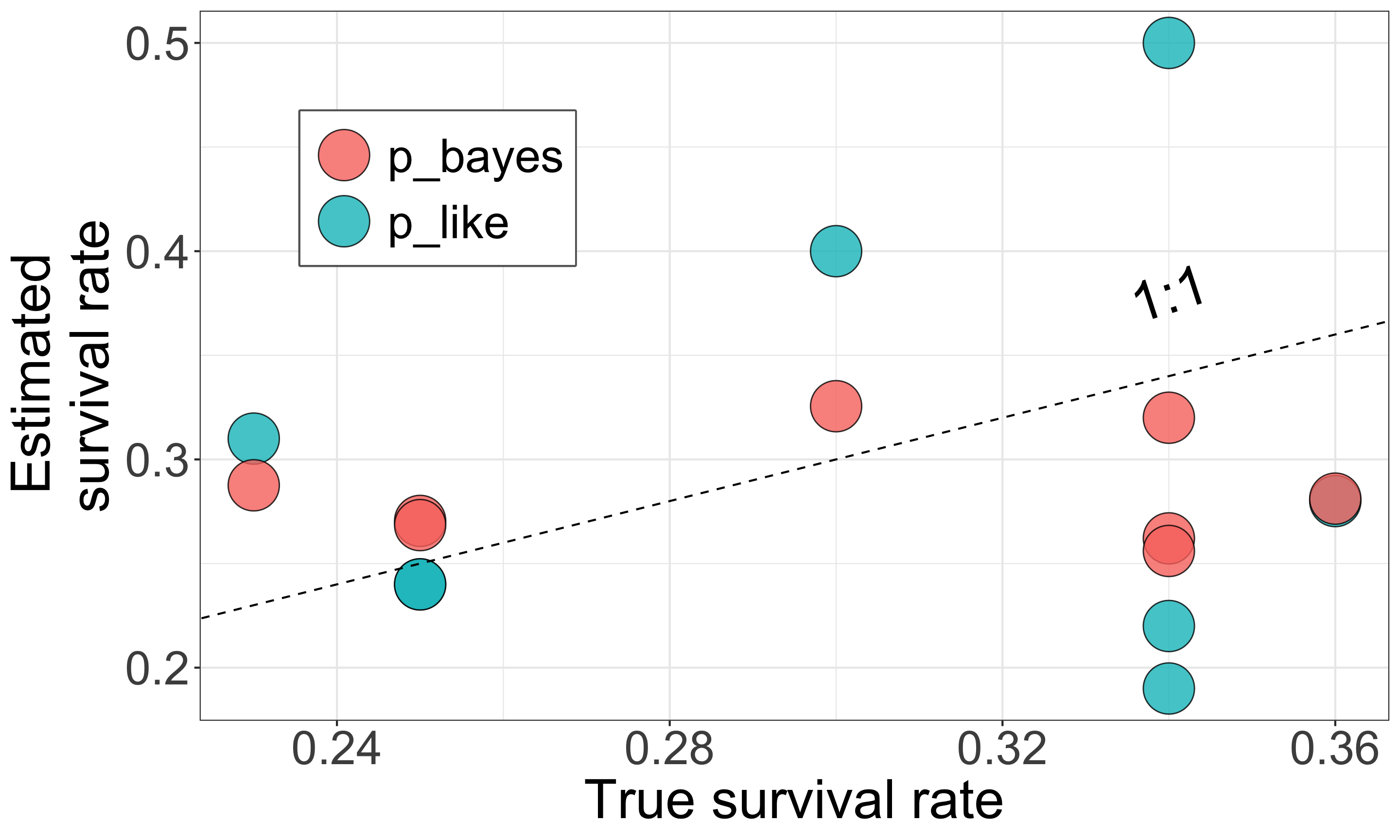
Closed symbols (
p_bayes) align more closely with the 1:1 line, indicating more accurate estimates.This model compensates for limited data by using prior knowledge that species responses are somehow similar and compensates for limited data.
References
Gelman, A. et al. Bayesian Data Analysis, Third Edition. (Chapman & Hall/CRC, 2013)
AIcia Solid Project (in Japanese and Math)
![]()