Likelihood and probability mass distribution (Poisson)
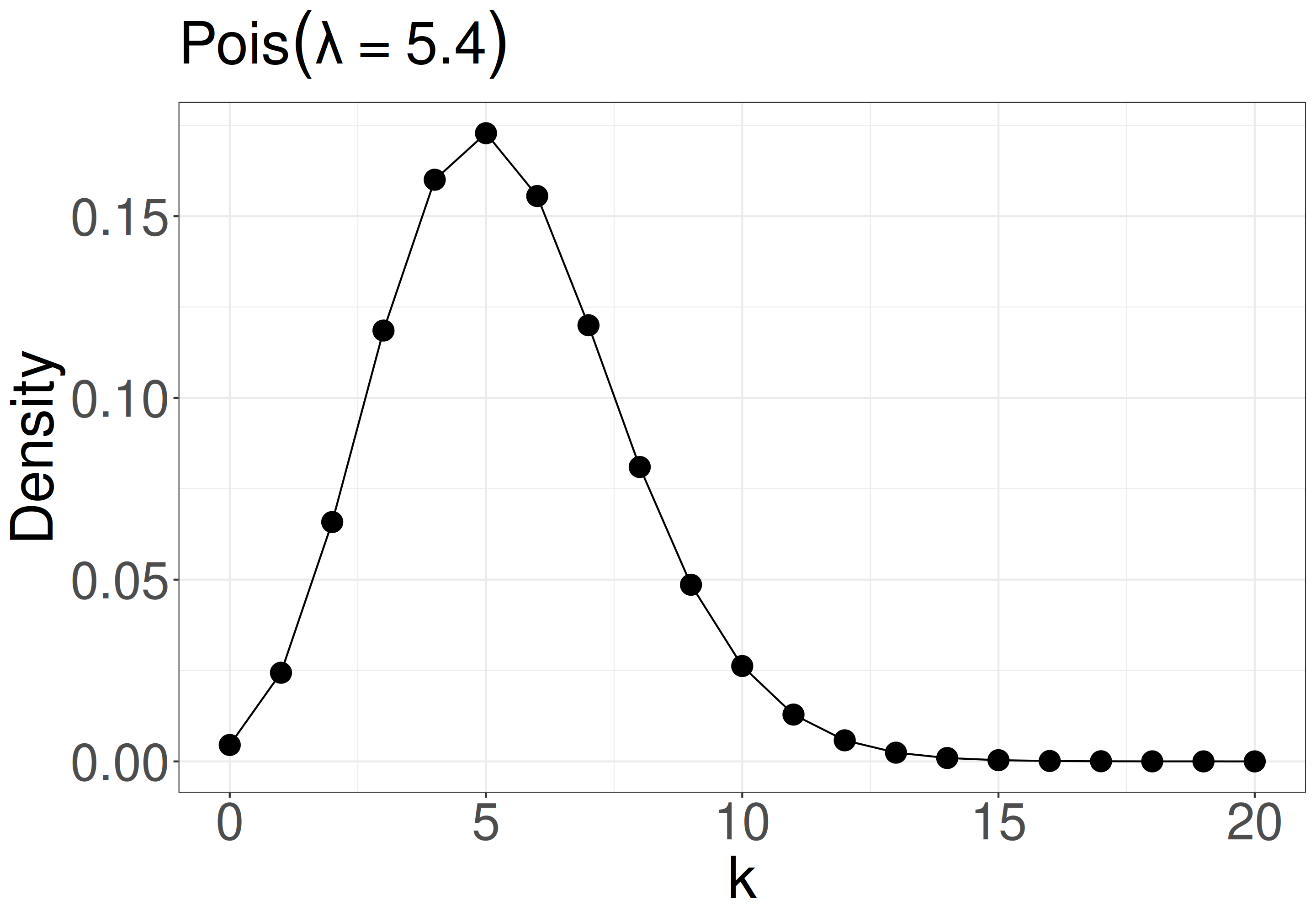
\(f(k \mid \lambda) = \frac{\lambda^k e^{-\lambda}}{k!}\)
P(data | parameters): Probability of observing the data given the parameters.
e.g., when your model is \(k_i \sim \mathcal{Pois}(\lambda = 5.4)\) (Poisson distribution with mean and variance = 5.4), what is the probability mass at k = 8?
- \(P(k = 8 \mid \lambda = 5.4)\)
Likelihood
Because we usually don’t know the true parameters (\(\mu\) and \(\sigma\)), we need to find the parameters that maximize the likelihood function (MLE: Maximum Likelihood Estimation).
e.g., for a linear model \(y_i = ax_i + b\), we usually assume that \(y_i \sim \mathcal{N}(\mu_i = ax_i + b, \sigma^2)\), and we want to find the parameters \(a\), \(b\), and \(\sigma\) that maximize the likelihood function: \(P(y_i \mid ax_i + b, \sigma)\)
In the previous example, \(\mu\) = 0 makes the likelihood maximum.
Maximum Likelihood Estimation (MLE)
- 2 survivors out of 5 seedlings: What is the survival probability of seedlings?

\(p\): survival rates, \(1-p\): mortality rate
\(L = {}_5C_2 p^2(1-p)^3\) (Binomial distribution)
\(\mathrm{ln}\;L = \mathrm{ln}\;{}_5C_2 + 2\mathrm{ln}\;p + 3\mathrm{ln}(1-p)\)
\(\frac{d}{dp}\mathrm{ln}\;L = \frac{2}{p} - \frac{3}{1-p} = 0\)
Solve: \(p = \frac{2}{5}\)

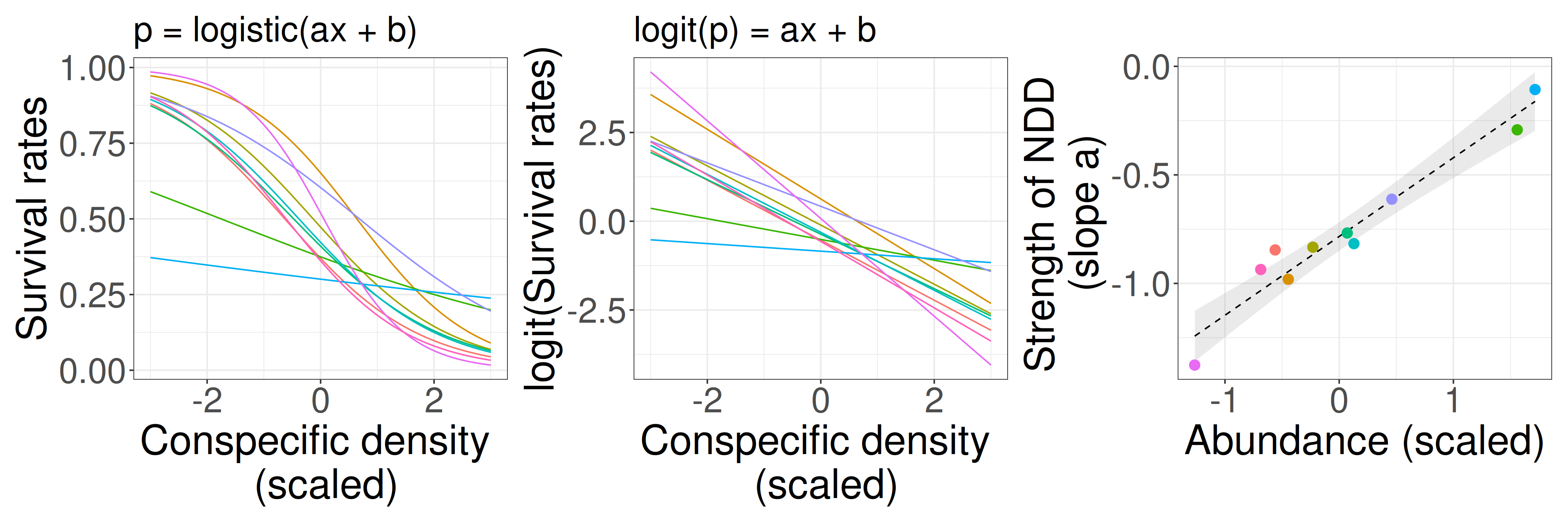
Negative density dependence (NDD)
“…rare species suffered more from the presence of conspecific neighbors than common species did, suggesting that conspecific density dependence shapes species abundances in diverse communities.”
- Comita et al. 2010 -
NDD can maintain diversity in communities by preventing common species from dominating the community.
Multilevel model (verbal model: NDD example)
H: Rare species tend to be rare because they suffer stronger conspecific NDD than common species.
There is negative density dependence (NDD) of seedling survival rate, and the strength of NDD varies among species. The strength of NDD depends on species abundance.
- Survival rates p ~ conspecific density x (individual-level, logistic regression).
- Slopes a ~ species abundance (species-level).
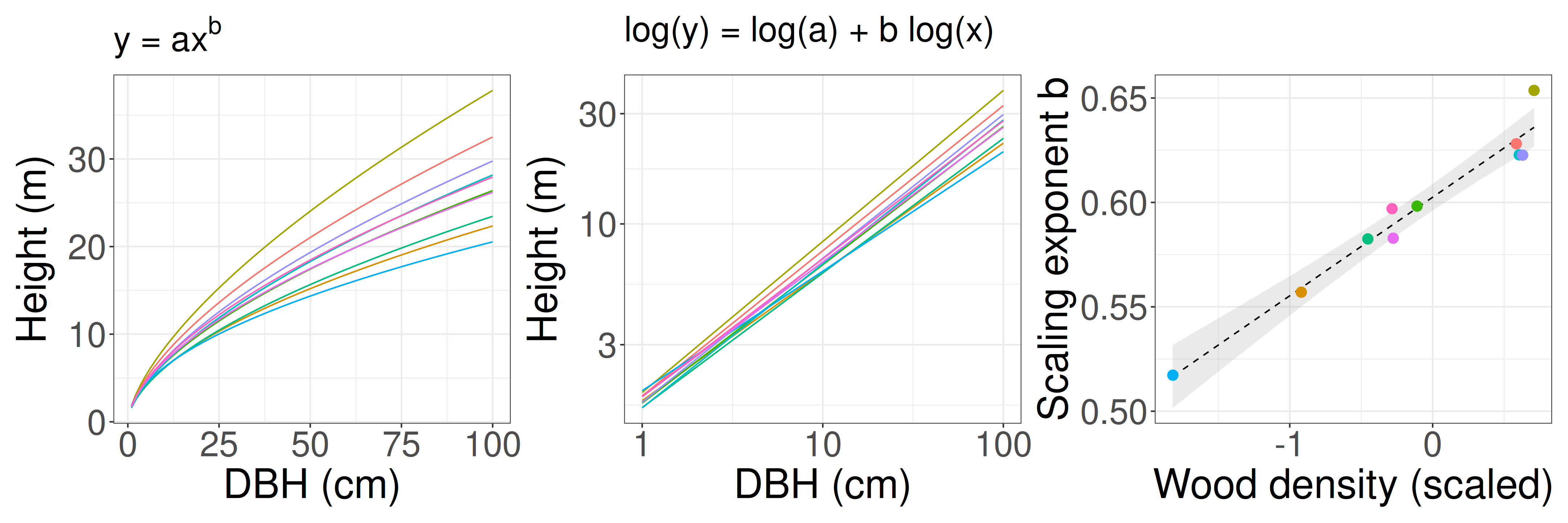
Multilevel model (verbal model: tree allometry example)
H: Dense wood can support taller trees than less dense wood.
There is a power-law relationship (\(y =ax^b\)) between tree diameter (DBH) and tree maximum height, and the power-law exponent varies among species. Those relationships depend on wood density.
Tree height y ~ DBH x (individual-level)
Slope b ~ wood density (species-level)
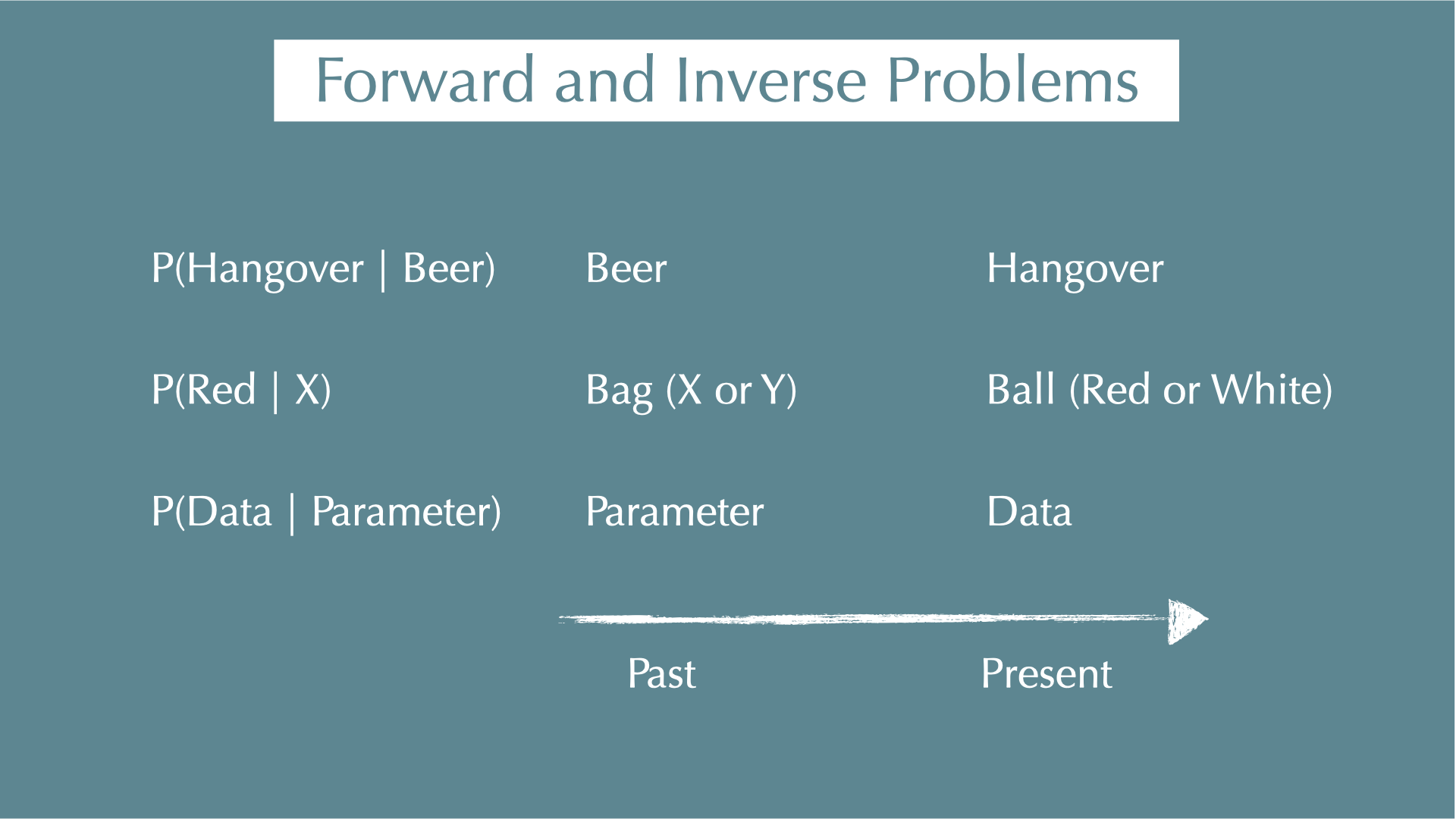
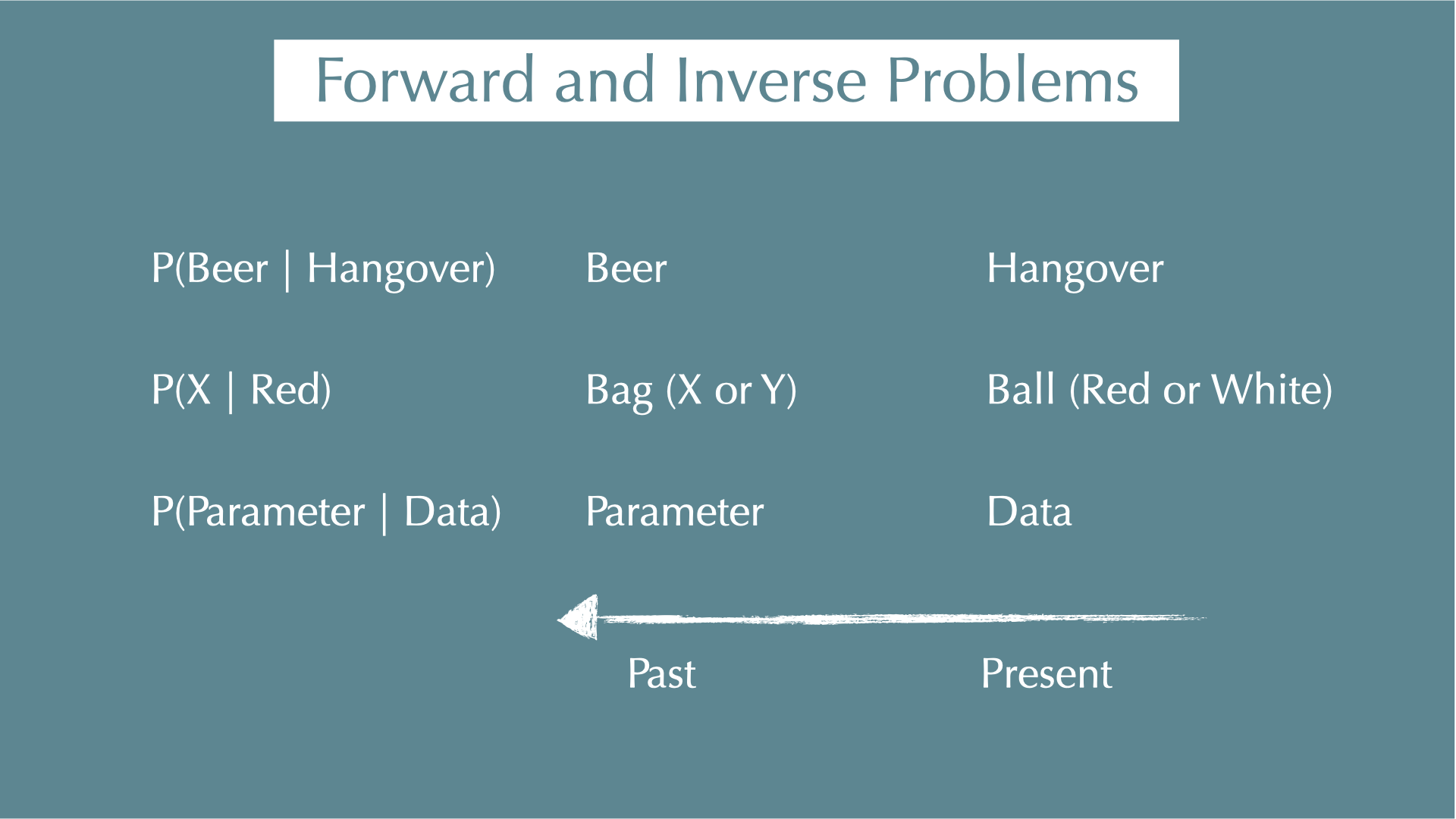
Probability
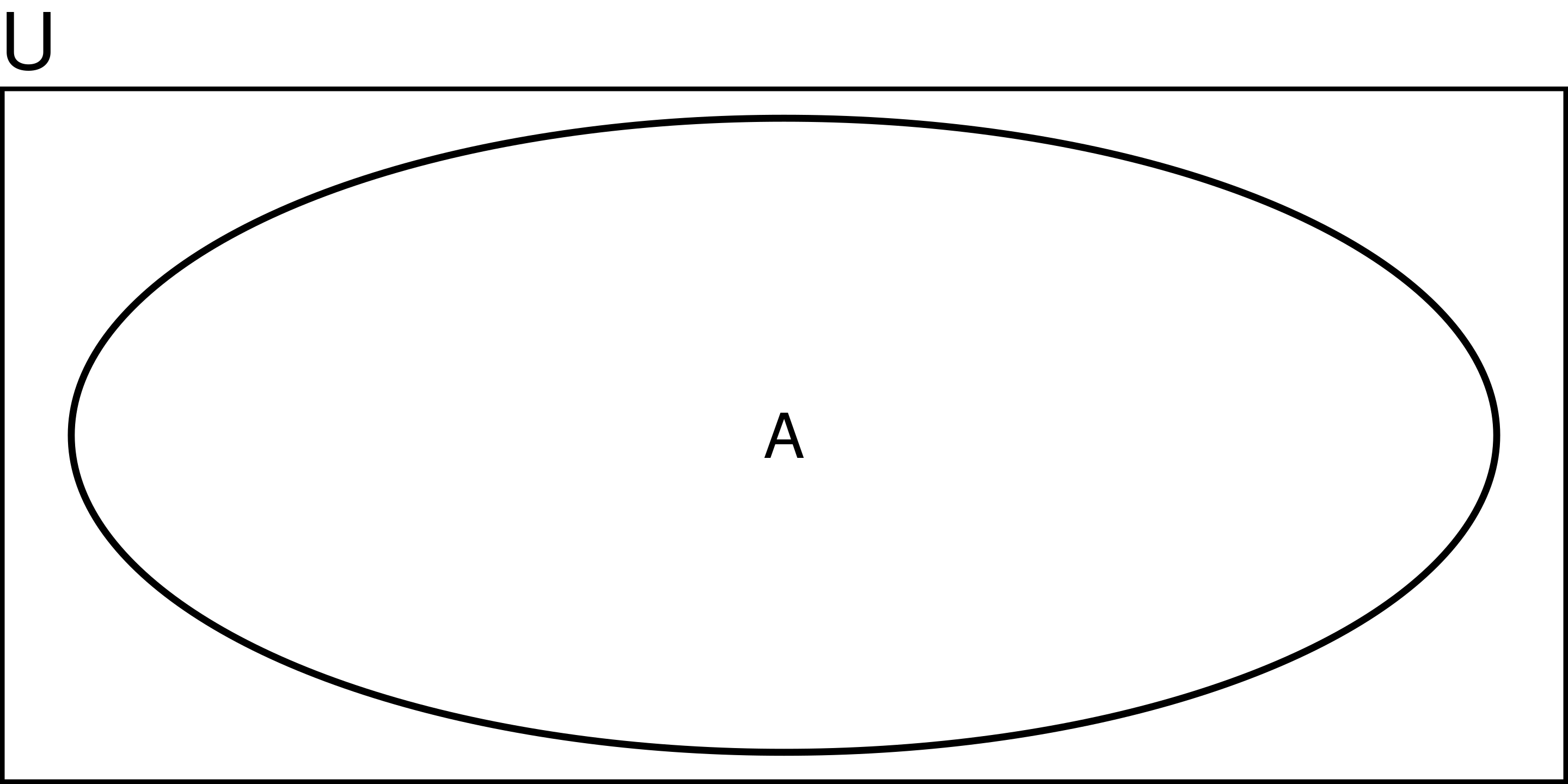
Probility of A:
\[ P(A) = \frac{A}{U} \]
e.g., probability of rolling a dice and getting an odd number is 3/6 = 1/2
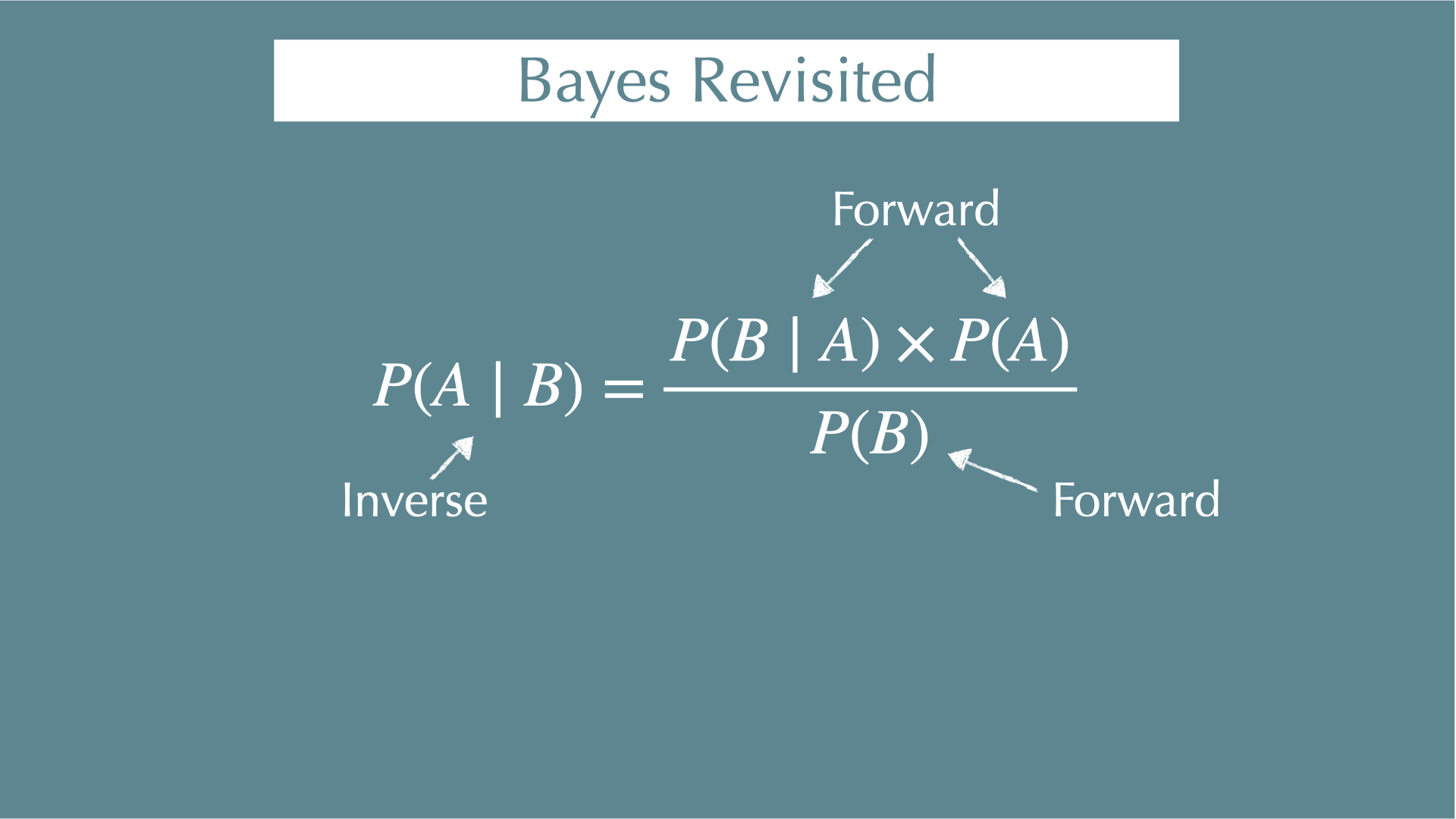
Conditional Probability
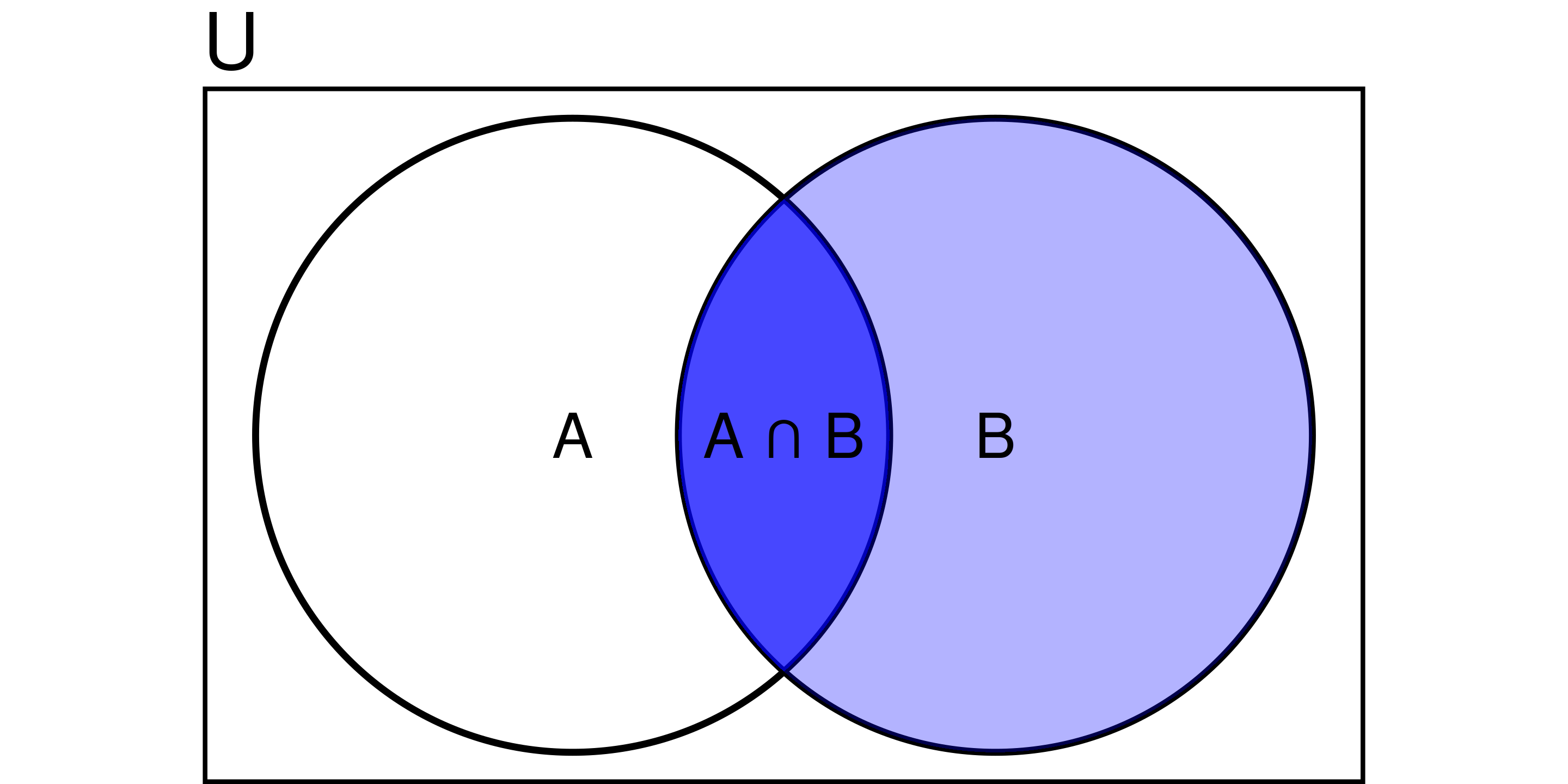
Probability of A occurring given B has already occurred:
\[ P(A \mid B) = \frac{P(A \cap B)}{P(B)} \]
e.g.,
- P(hangover) = 4%
- P(baiju) = 1.5%
- P(hangover | baiju) = 85%.




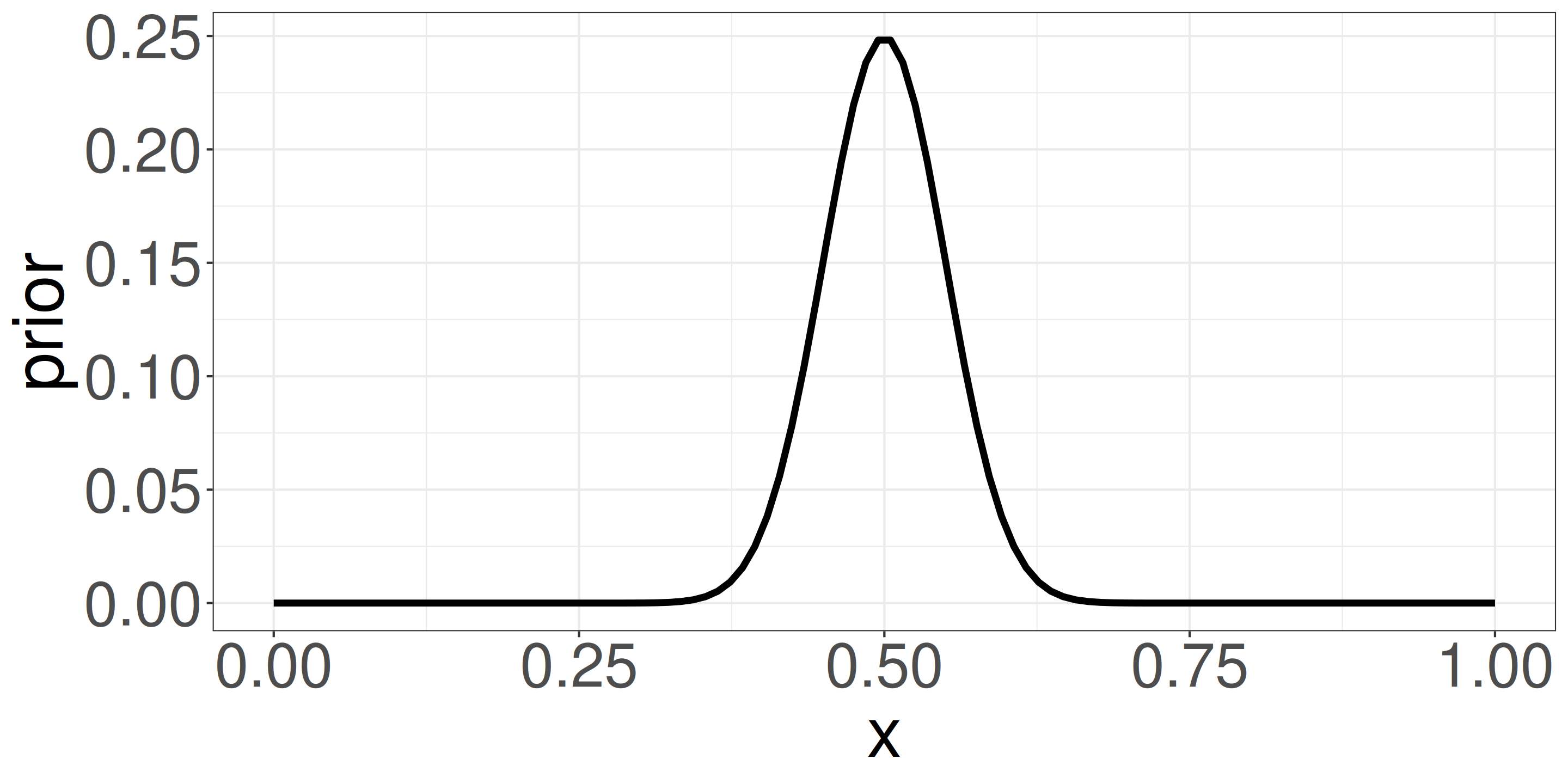
Prior

Prior vs. Data: MLE and Bayesian comparison (Coin Toss)
We compare two coins, A and B, with the same prior but different likelihood (due to data sizes) to illustrate how prior beliefs influence posterior estimates.
MLE
- A: 2 head out of 3 tosses -> P(H) = 2/3 = 0.666
- B: 60 heads out of 100 tosses -> P(H) = 60/100 = 0.6
Bayesian
\(\textcolor{#1b9e77}{L_A = {}_3C_2 p^2 (1-p)^1}\)
\(\textcolor{#1b9e77}{L_B = {}_{100}C_{60} p^{60} (1-p)^{40}}\)
\(\textcolor{#7570b3}{\mathrm{Prior} \propto p^{50} (1-p)^{50}}\)
- Beta distribution with mean 0.5 and small variance (strong prior example).
Priors in ecology: Why scale matters
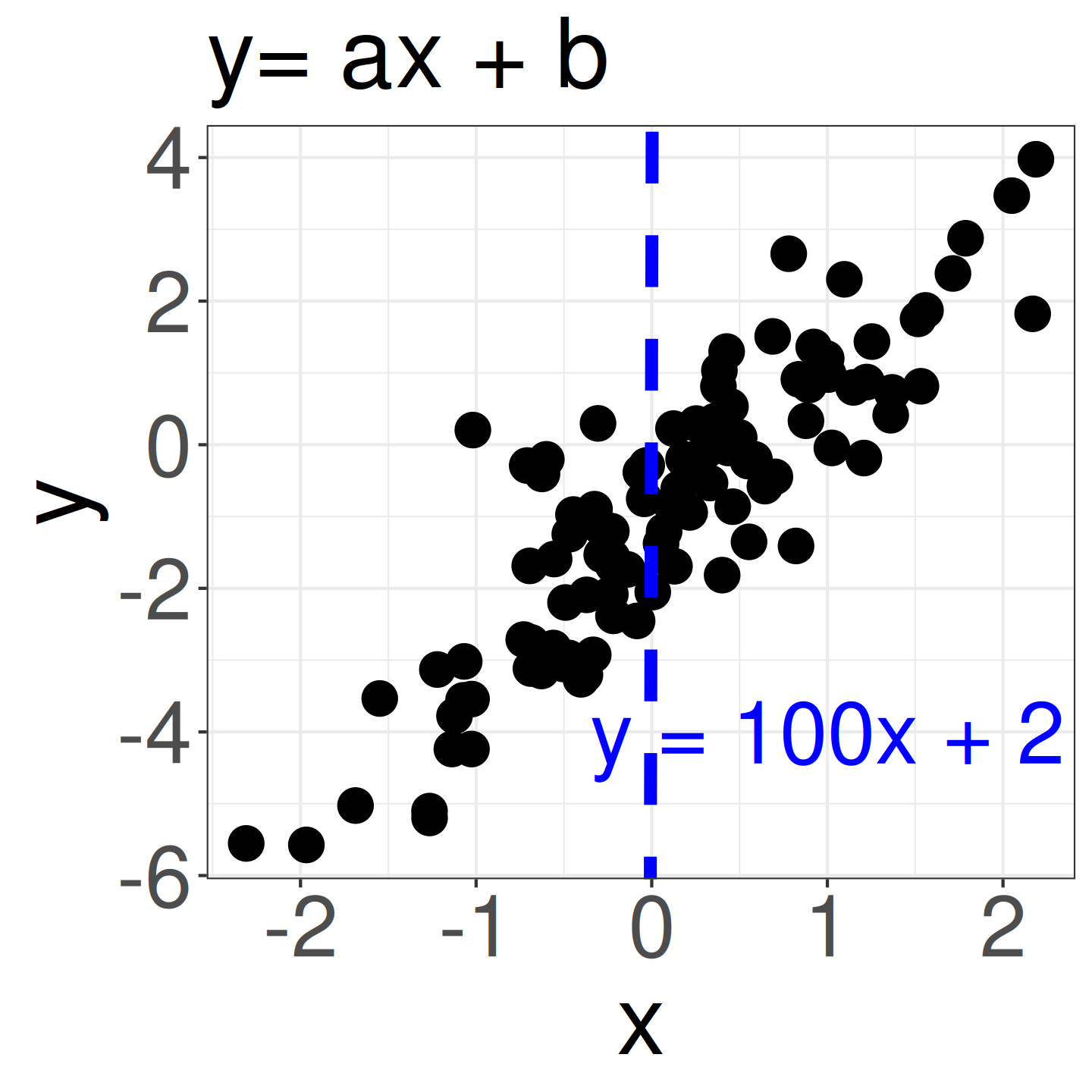
- We consider variables x = {-3, …, 3} and y = {-6, …, 4}. We don’t yet know if there is a correlation (y = ax + b).
- However, a slope like a = 100 (blue line) clearly doesn’t match the data (i.e., uninformative prior: \(a \sim \mathcal{N}(0, 10^4)\)).
- Given the similar scales of x and y, it’s reasonable to guess that a falls within a narrow range (e.g., strongly informative prior: -5 to 5, weakly informative prior: \(a \sim \mathcal{N}(0, 2.5)\)).
Priors and ecology: multilevel structure for group-level effects
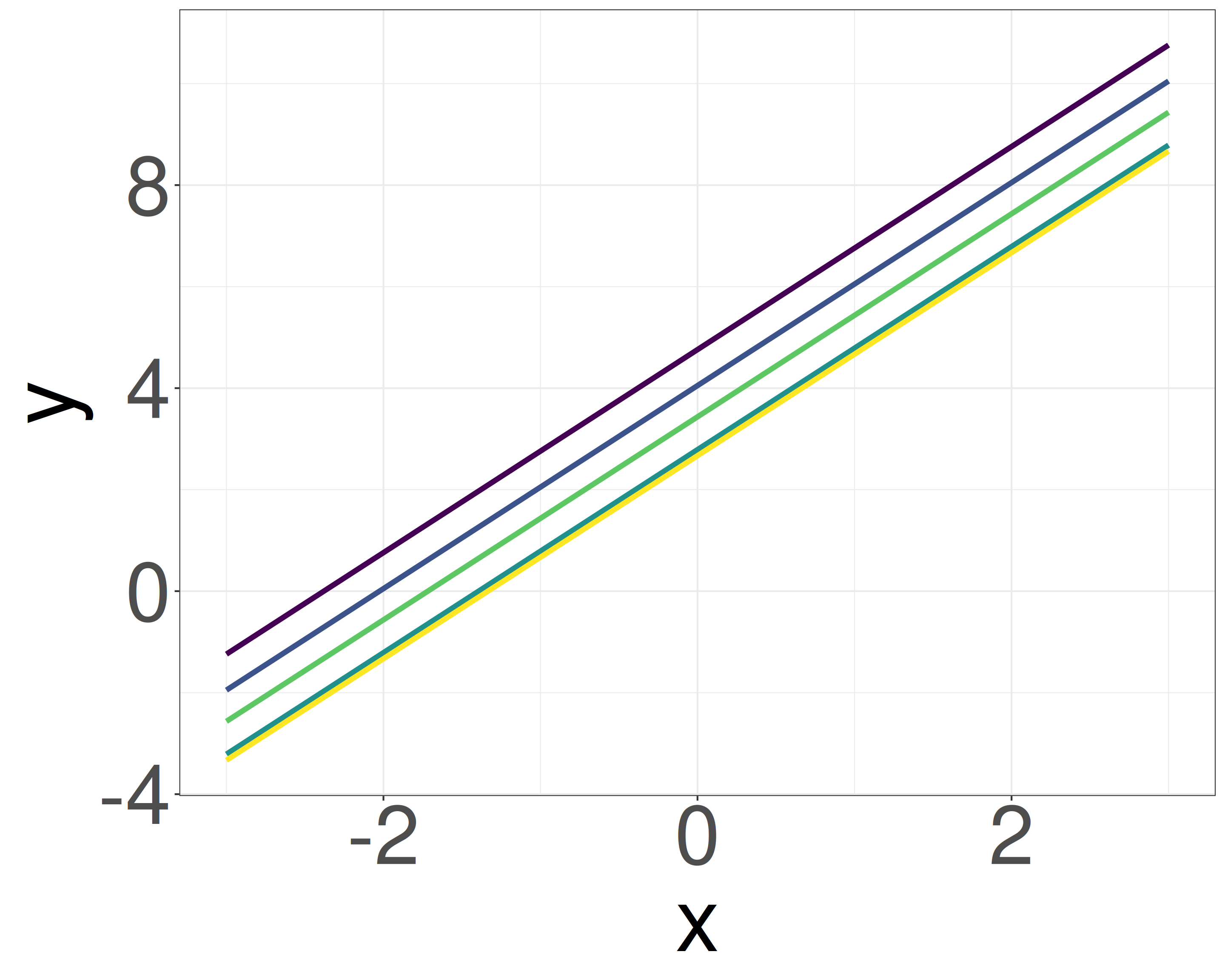
- Likelihood: \(y_i \sim \mathcal{N}(ax_i + b_j, \sigma)\)
- If the parameter \(b_j\) is similar within each group (e.g., species differences, site differences), it makes sense to model:
- Prior: \(b_j \sim \mathcal{N}(\mu_b, \tau)\)
- \(\mu_b\): global means across all groups
- \(\tau\): variation among groups
Priors and ecology: multilevel structure for spatial autocorrelation
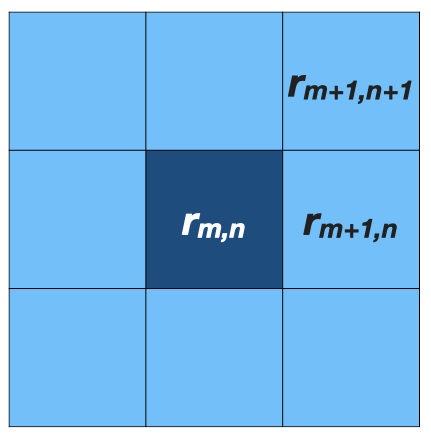
- When the data \(y_i\) is similar to the surrounding samples (e.g., temporal / spatial autocorrelation):
- Likelihood: \(y_i \sim \mathcal{N}(\mu + \tilde{r_i}, \sigma)\)
- Prior (spatial effect): \(\tilde{r_i} = r_{m, n} \sim \mathcal{N}(\phi_{m,n}, \tau)\)
- \(\phi_{m,n}\) = average of 8 neighbors around \(r_{m,n}\)
\[ \begin{align*} \phi_{m,n} = \frac{1}{8} (& r_{m-1,n-1} + r_{m-1,n} + r_{m-1,n+1} + \\ & r_{m,n-1} + r_{m,n+1} + \\ & r_{m+1,n-1} + r_{m+1,n} + r_{m+1,n+1}) \end{align*} \]
Eight schools problem
Coaching effects in eight schools.

Eight mother trees problem (separate estimates)
What is the survival rate?
| id | n | suv | p_like | p_true |
|---|---|---|---|---|
| A | 41 | 9 | 0.22 | 0.34 |
| B | 45 | 18 | 0.40 | 0.30 |
| C | 32 | 6 | 0.19 | 0.34 |
| D | 18 | 5 | 0.28 | 0.36 |
| E | 33 | 8 | 0.24 | 0.25 |
| F | 26 | 8 | 0.31 | 0.23 |
| G | 46 | 11 | 0.24 | 0.25 |
| H | 16 | 8 | 0.50 | 0.34 |
p_trueranges [0.23, 0.36]p_likeranges [0.19, 0.5]The estimate shows the larger variation
Because of the small sample size (common in ecological studies)
Extreme case 1: Pooled estimates
- \(S_i \sim \mathcal{B}(N_i, p)\): Likelihood
- \(\mathrm{logit}(p) \sim \mathcal{N}(0, 2.5)\): Prior
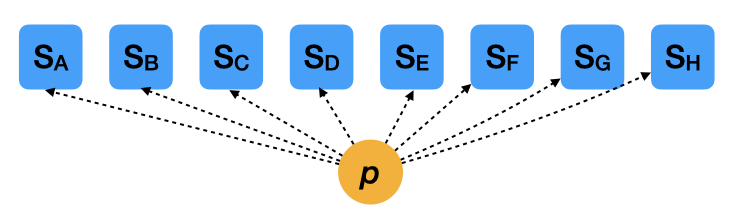
- This model assumes all mother trees share the exact same survival rate.
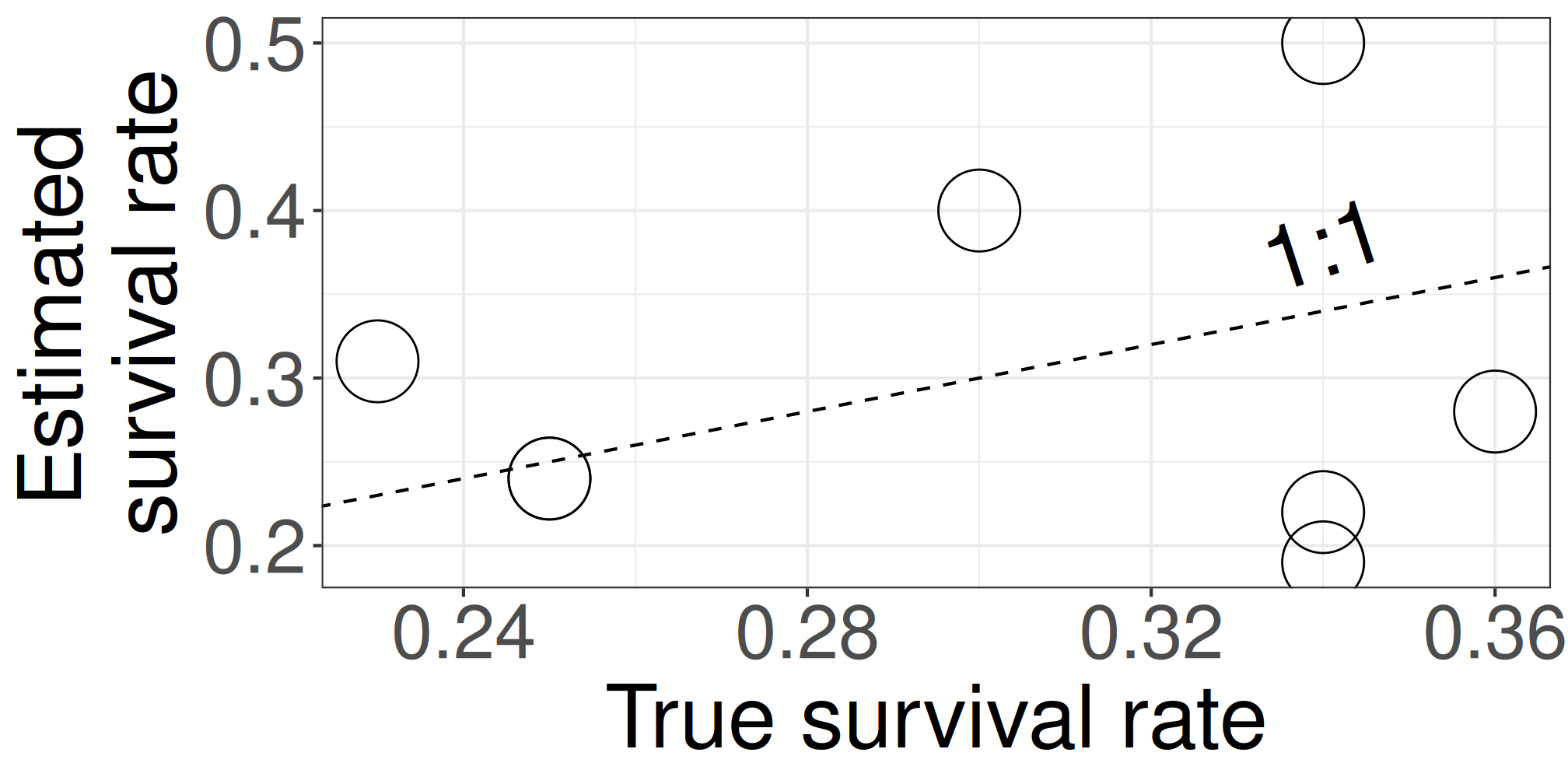
Extreme case 2: Separate estimates
- \(S_i \sim \mathcal{B}(N_i, p_i)\): Likelihood
- \(\mathrm{logit}(p_i) \sim \mathcal{N}(0, 2.5)\): Prior
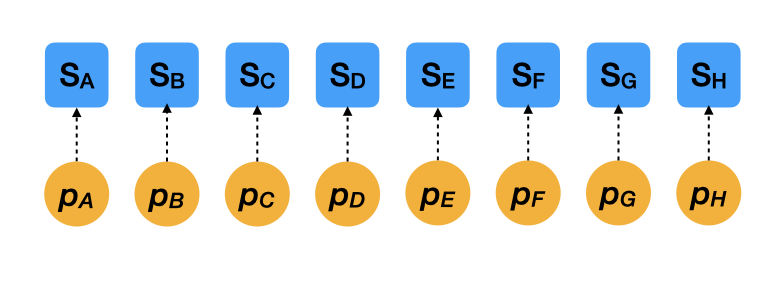
- This model assumes each mother tree has a completely independent survival rate.
- With limited data per tree, this model tends to overfit and produces noisy estimates.
- We need to find a balance between these two extremes.
More realistic estimates: Multilevel models — partial pooling
\(S_i \sim \mathcal{B}(N_i, p_i)\): Likelihood
\(\mathrm{logit}(p_i) \sim \mathcal{N}(\mu, \sigma)\): Group-level model (hierarchical prior)
\(\mu \sim \mathcal{N}(0, 2.5)\): Hyperprior
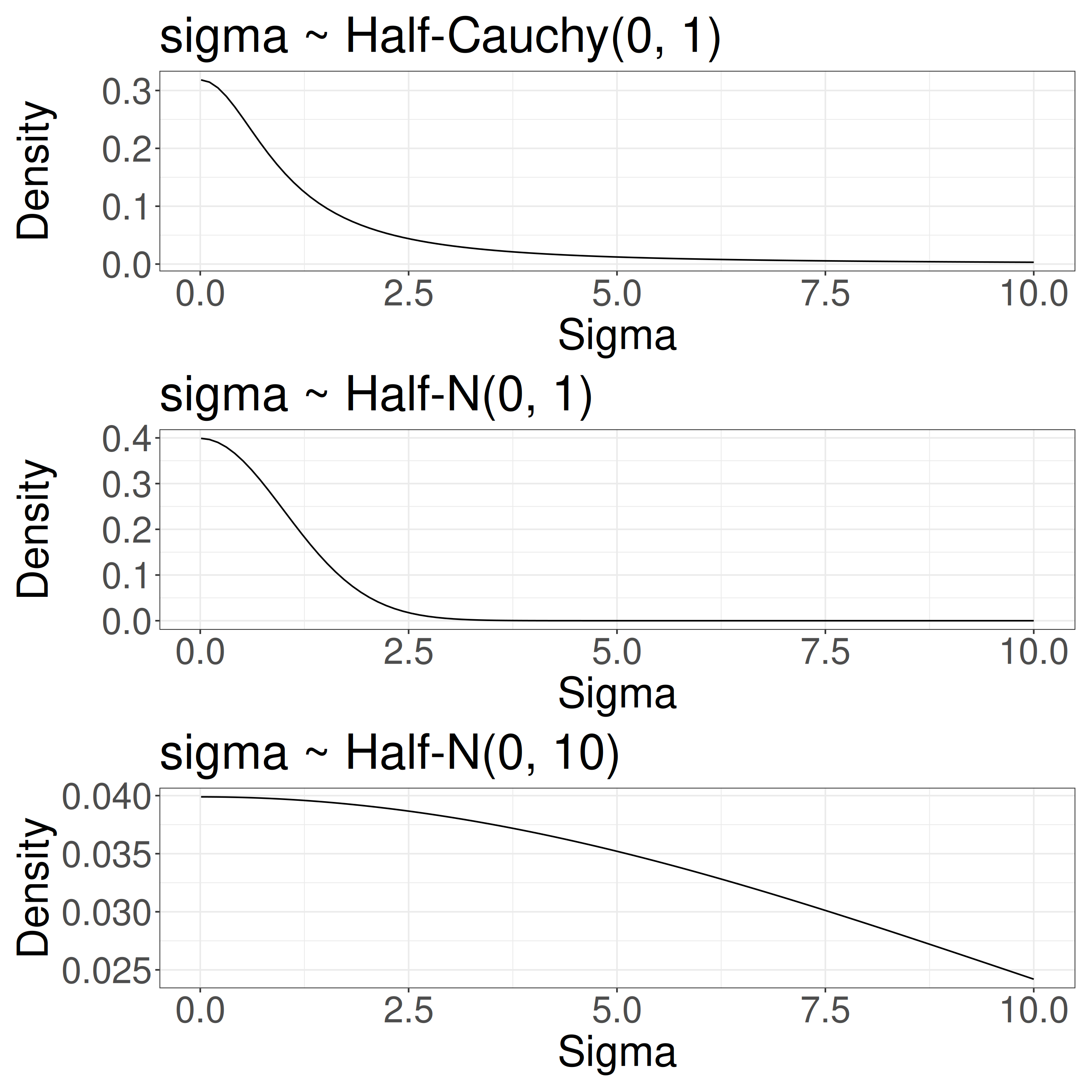
\(\sigma \sim \text{Half-Cauchy}(0, 1)\): Hyperprior
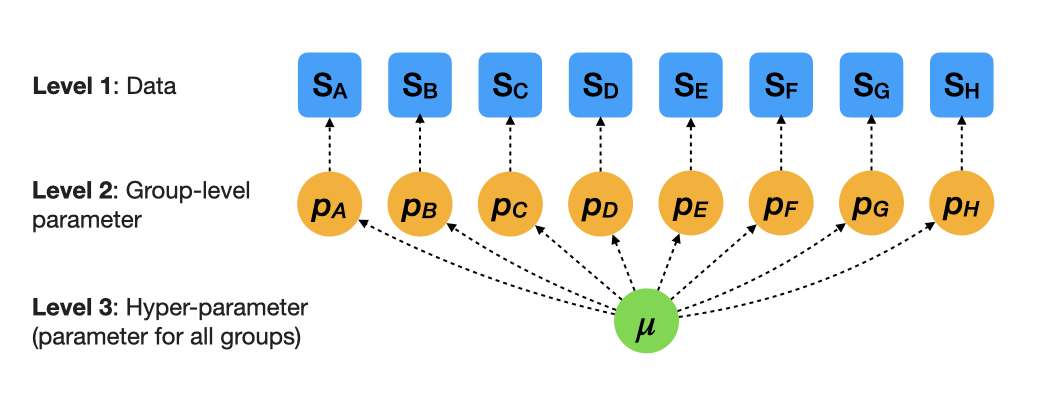
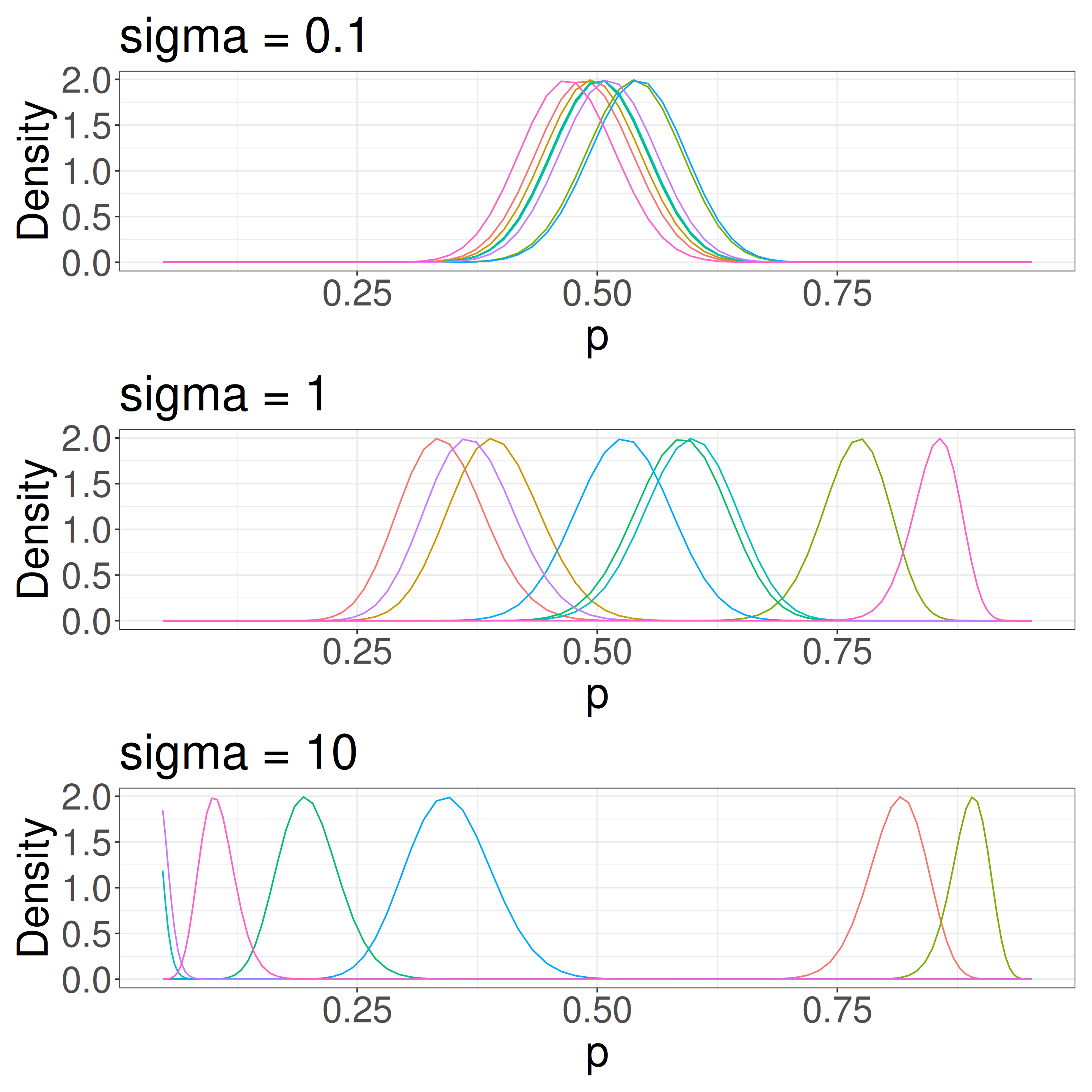
\(\sigma\) determines group-level variation
The overall survival rate is 0.5 in this figure. We have some sense of a scale for \(\sigma\).
Better estimates via partial pooling (Bayesian multilevel model vs. MLE separate fits)
| sp | n | suv | p_like | p_true | p_bayes |
|---|---|---|---|---|---|
| A | 41 | 9 | 0.22 | 0.34 | 0.26 |
| B | 45 | 18 | 0.40 | 0.30 | 0.32 |
| C | 32 | 6 | 0.19 | 0.34 | 0.25 |
| D | 18 | 5 | 0.28 | 0.36 | 0.28 |
| E | 33 | 8 | 0.24 | 0.25 | 0.27 |
| F | 26 | 8 | 0.31 | 0.23 | 0.29 |
| G | 46 | 11 | 0.24 | 0.25 | 0.27 |
| H | 16 | 8 | 0.50 | 0.34 | 0.32 |
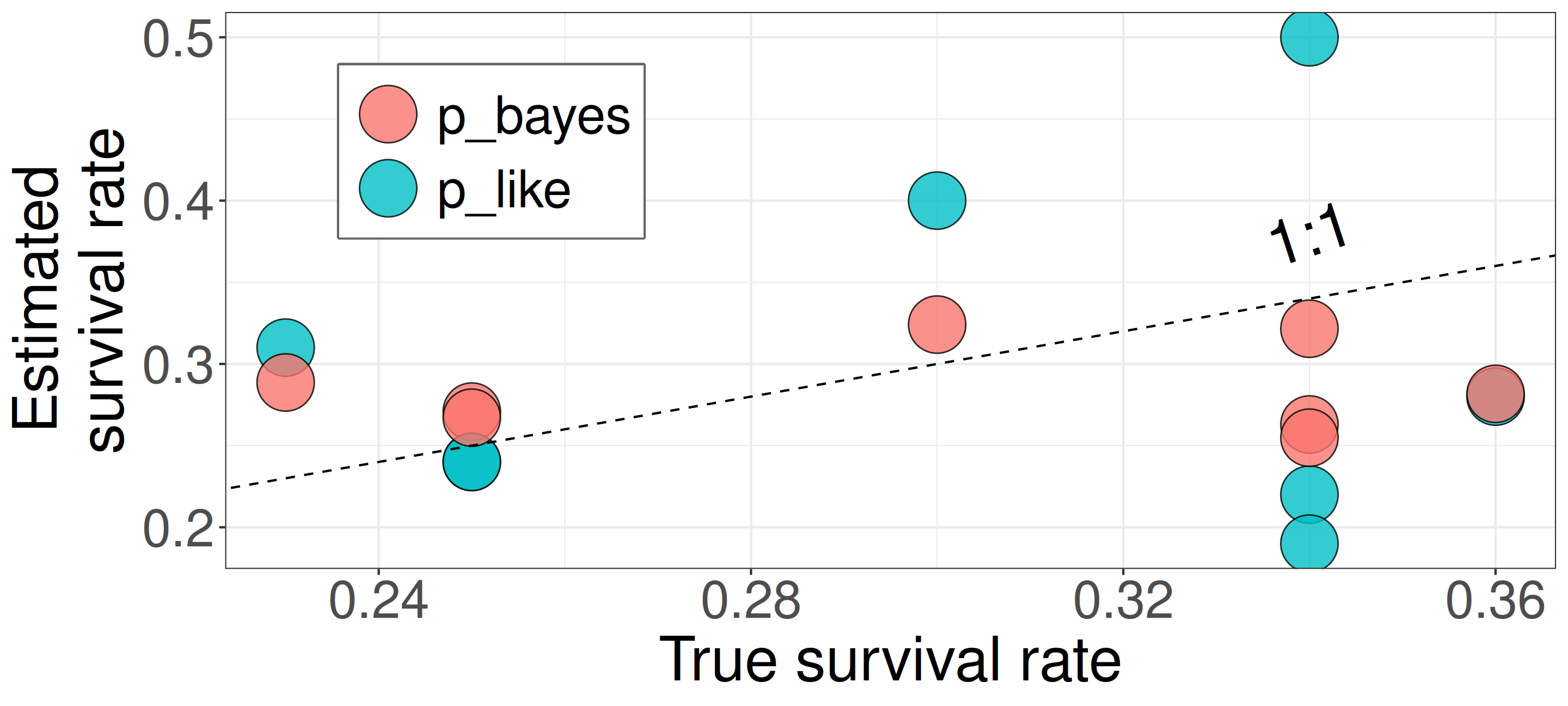
Closed symbols (
p_bayes) align more closely with the 1:1 line, indicating more accurate estimates.This model compensates for limited data by using prior knowledge that tree responses are somehow similar and compensates for limited data.
Tools for Bayesian Modeling

- Basic idea of MCMC
- Stan: A modern language for Bayesian modeling
- Interfaces to Stan
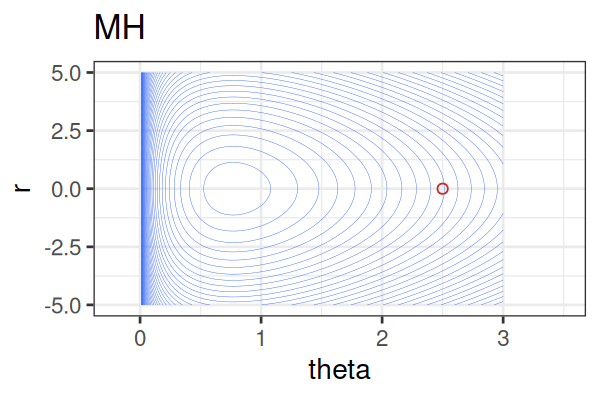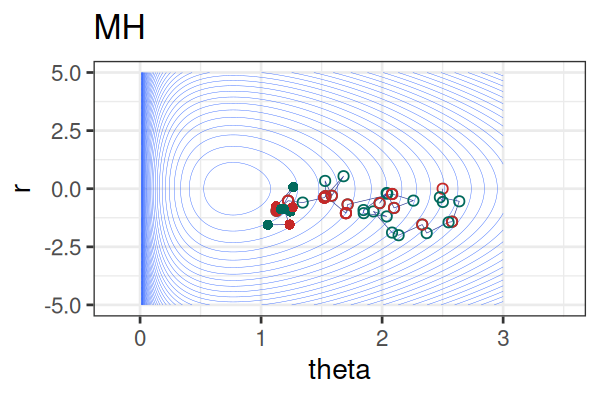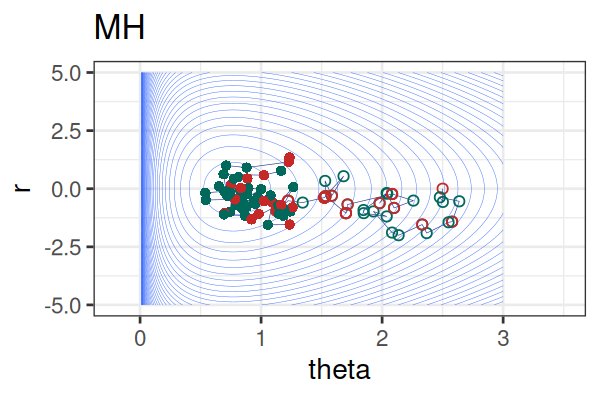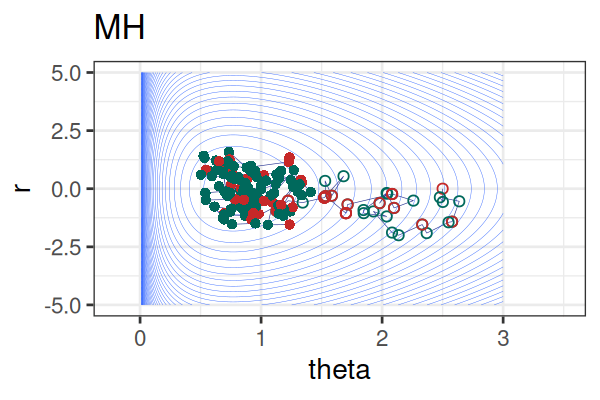
MCMC: a simplified Metropolis-Hastings (MH) algorithm
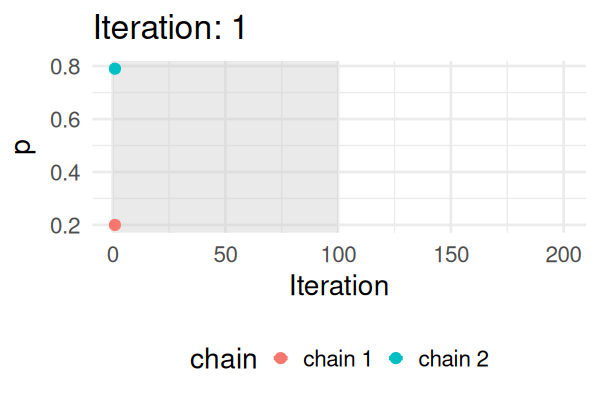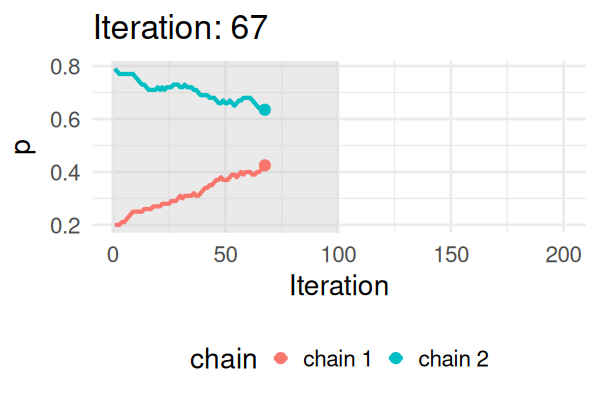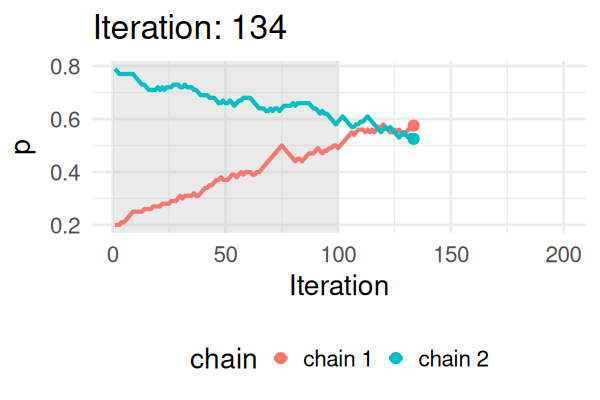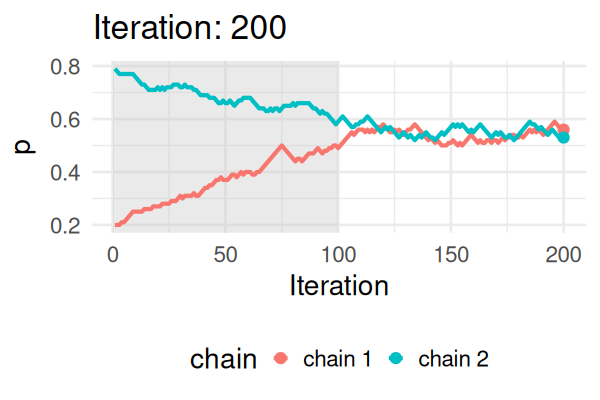
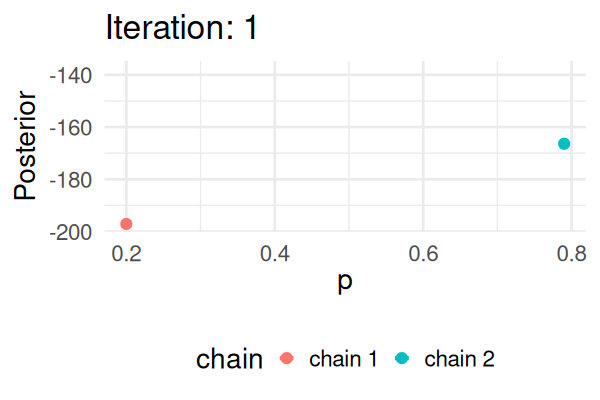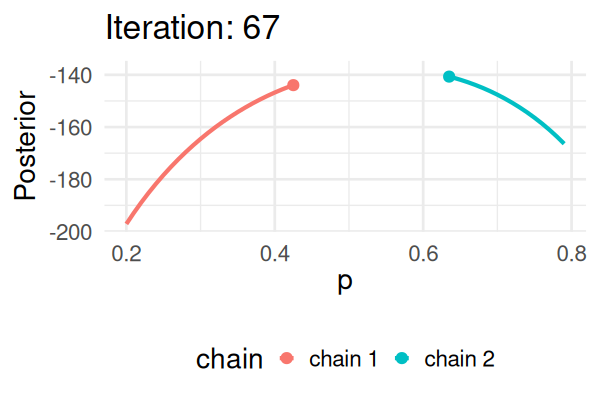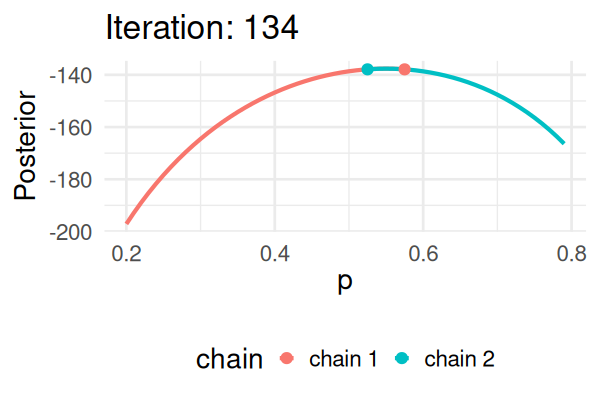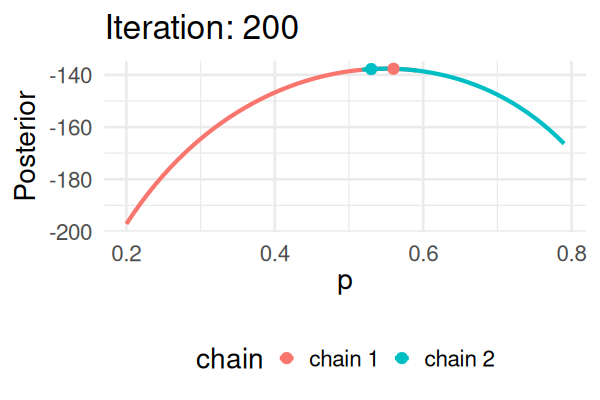
- Start with some values of p (e.g., 0.2 and 0.8).
- Caclulate the posterior of those values.
- Repeat the following steps N times:
- Propose a new value of \(p_{\text{new}}\) (e.g., \(p \pm 0.01\))
- Calculate the posterior at \(p_{\text{new}}\).
- If \(\text{Post}(p_{\text{new}}) \geq \text{Post}(p_t), \text{ then } p_{t+1} = p_{\text{new}}\).
- Else, accept \(p_{\text{new}}\) with probability \(\frac{\text{Post}(p_{\text{new}})}{\text{Post}(p_t)}\).
MCMC: Hamiltonian Monte Carlo (HMC)
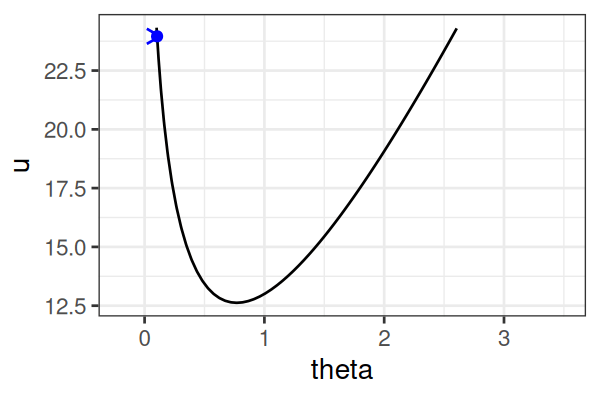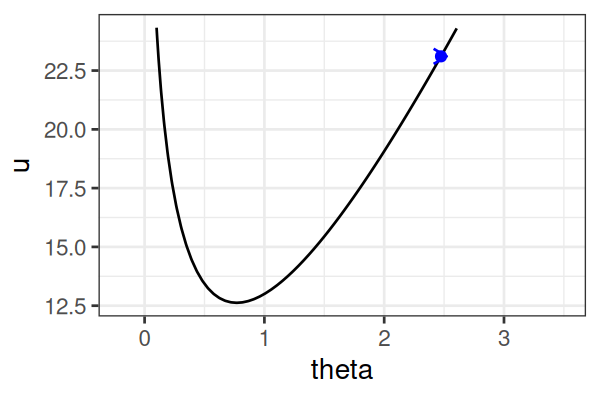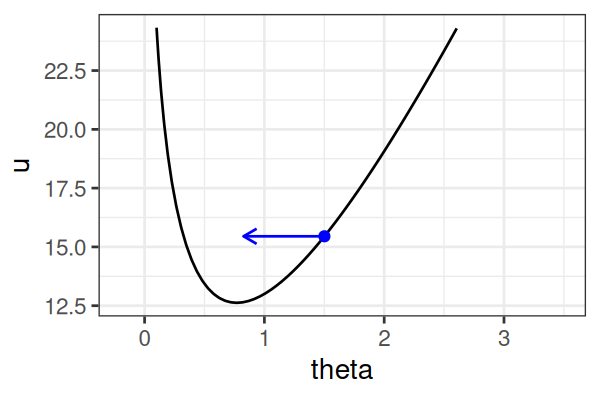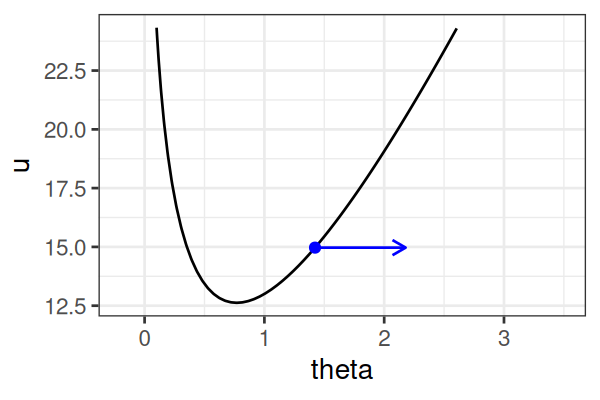
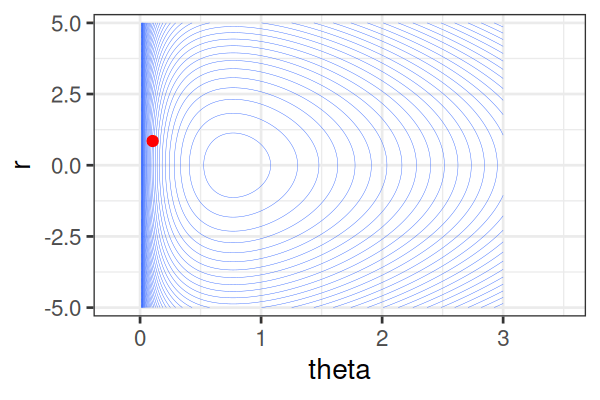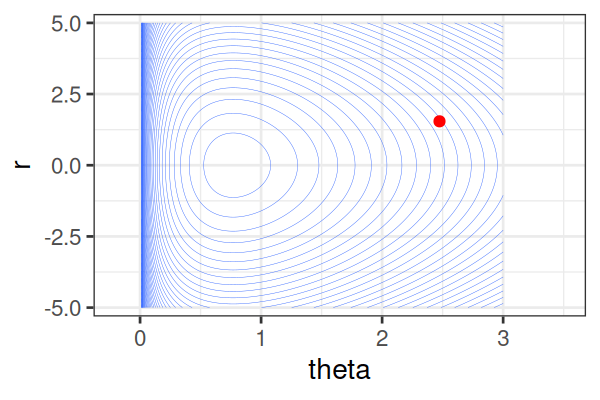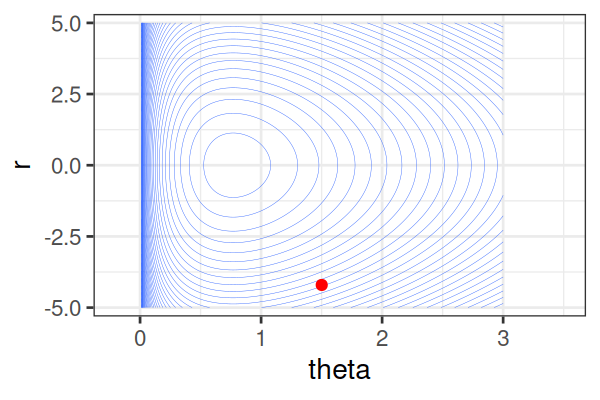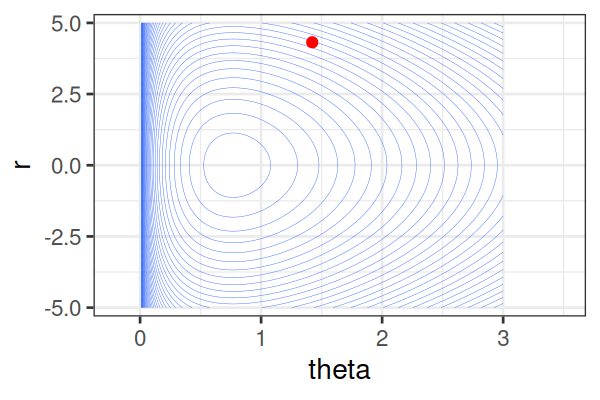
\(H(\theta, r) = U(\theta) + r^2/2\) (Hamiltonian: potential energy + kinetic energy = constant)
- \(U(\theta) = -\text{log}\; p(\theta \mid \text{data})\) ()
Instead of sampling from \(p(\theta \mid \text{data})\), HMC samples from a joint distribution over both \(\theta\) and \(r\).
- \(p(\theta \mid \text{data}) \propto \int \text{exp}(-H(\theta, r))dr\)
It’s equivalent to sampling from \(p(\theta \mid \text{data}) \propto \text{exp}(-U(\theta))\).
HMS explores very different \(\theta\) along the same trajectory (i.e. leapfrog path), which is much more efficient than random sampling.
MCMC: Hamiltonian Monte Carlo (HMC)
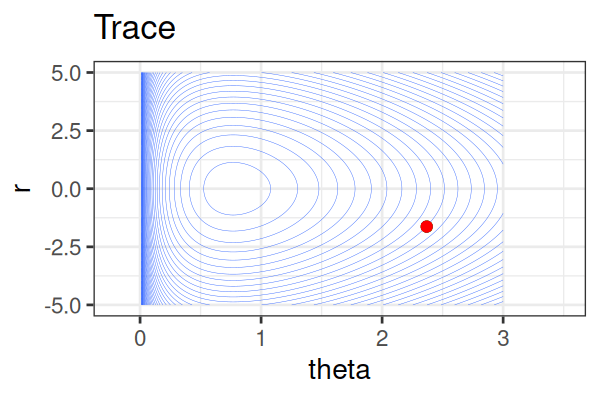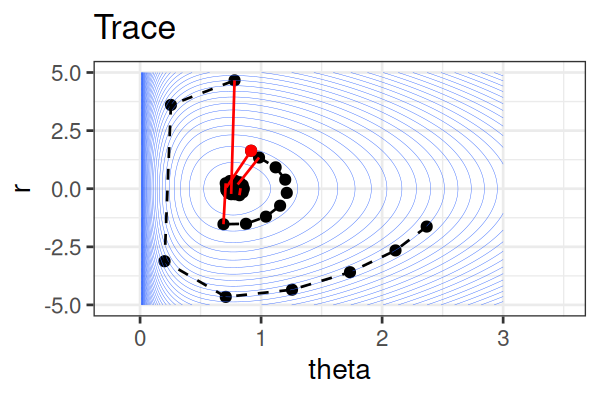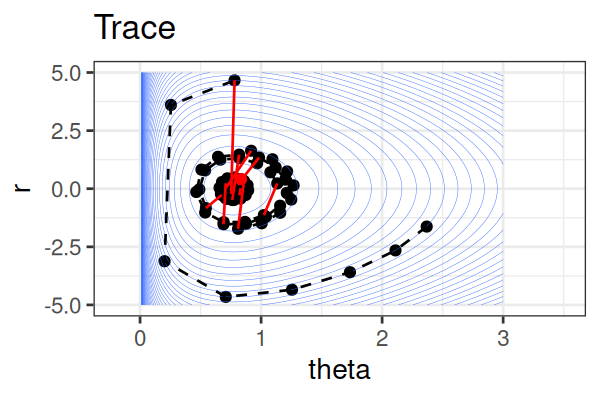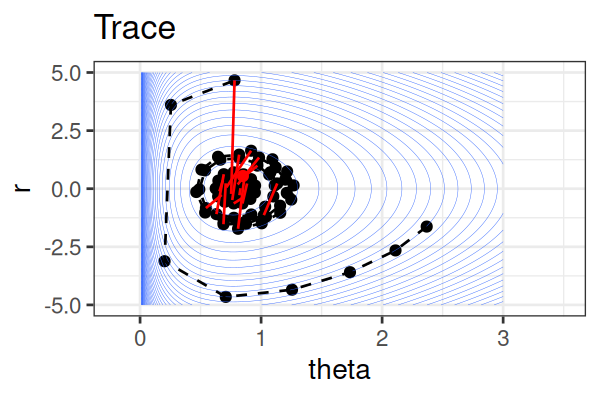
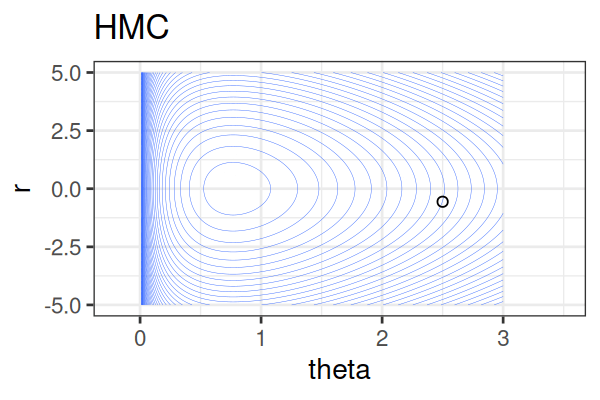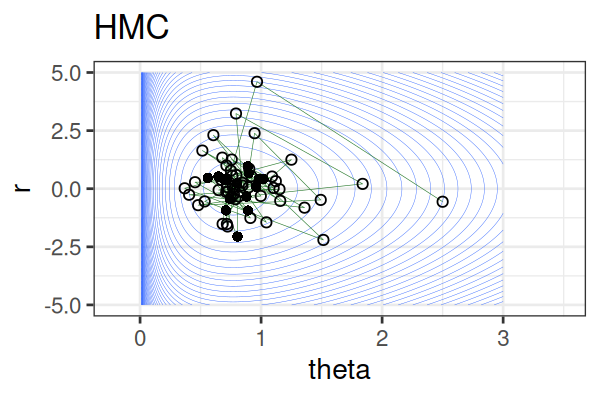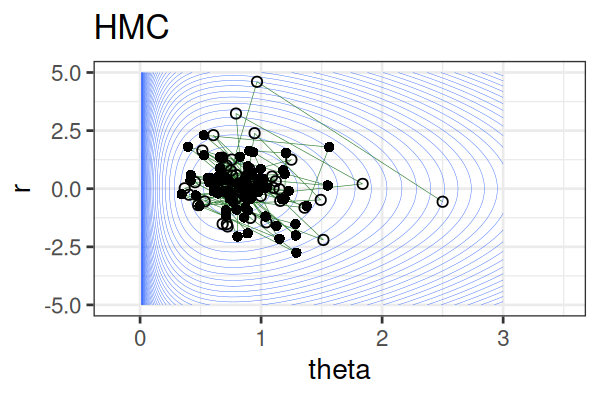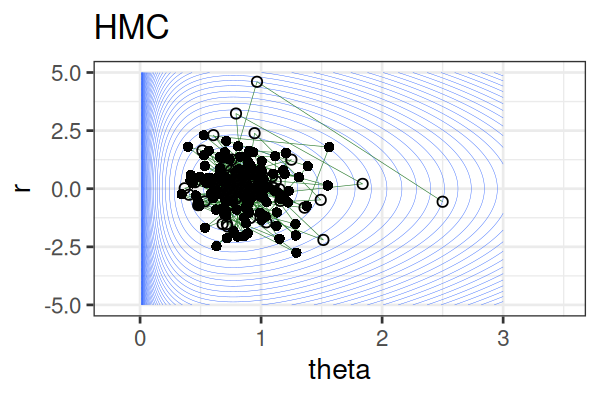
Within each iteration, HMC simulates a trajectory using leapfrog steps.
- No-U-Turn Sampler (NUTS) dynamically determines the number of leapfrog steps; we only need to set the maximum (e.g.,
max_treedepthin Stan).
- No-U-Turn Sampler (NUTS) dynamically determines the number of leapfrog steps; we only need to set the maximum (e.g.,
The Hamiltonian stays almost constant, but momentum \(r\) is resampled each iteration.
Only the final parameter \(\theta\) of each trajectory is kept as a posterior sample.
MCMC: HMC vs. Metropolis-Hastings (MH)
Stan: A modern language/software for Bayesian modeling
![]()
Bayesian Modeling
- Stan uses the No-U-Turn sampler (NUTS), a variant of Hamiltonian Monte Carlo (HMC), which is efficient for complex models with many parameters.
Flexible and Scalable
- You can use Stan for many types of models, from simple regressions to multi-level models including time-series, spatial, SEM, and more.
Multiplatform
- Stan works with R, Python, Julia, and more. It also has tools for checking models and making visualizations.